¶ 1 Overview and main features
The RED framework was built for Exasol as an Auto-ELT framework. RED is 100% matadata driven and manages all tasks around loading, historising and securing data. Loading data from heterogenous sources (like databases, files or REST-APIs) is accomplished through asynchronous, highly parallelised processes. However, no manual configuration or tuning is needed, no external schedulers are involved and there is no need for building manual transformation pipelines.
Furthermore, this RED framework contains prefabricated building blocks, which allows for individualised projects to be realised in a very short time. Another advantage of this framework is that, by merging the data of different databases and other files, a secure and high-performance analysis of these large amounts of data is possible, without having to make special adjustments or using tuning mechanisms. Even complex queries can be made due to this framework.
The next paragraphs deal with the main features of the RED framework in more detail.
¶ 1.1 Shortest Project Turnaround Times
Loading a new source with complete historization into the analytical database is simple and only takes filling out the following metadata in the relevant tables:
- Define the location of the source
- Define a unique key (Business Surrogate Key (BSK)) and the type of historization (event or period data)
- Define load cycles (calendar logic)
- Define security (on object, row and column level)
- Activate the loading
Each of the options mentioned above, will be explained in more detail in the following chapters.
This declarative approach with its built-in calendar control and implicit dependency analysis eliminates the need for elaborate job designs and custom code writing. Furthermore, usually there is no core model, as the extreme performance of the database does not require it. Instead, a virtual layer can be built in the form of views, if, for example, a BI tool requires such. However, the data, which is automatically transferred 1:1 with unchanged structures, but completely and traceably historized, is stored in tables and is directly available to the department via such a view layer.
¶ 1.2 Automated Operation
In operation, the extraction of data sources takes place near real time via direct connections to the data source or via file load. The loading is highly parallel and asynchronous. No jobs need to be defined and dependencies within the data are recognised implicitly.
After the automated, complete historization of the data, it is stored in the Persistent Staging Area. Conversions or transformations of the data are usually not necessary. However, if these are needed in special cases, they can be integrated via another view layer.
¶ 1.3 Complete Historization
Historization allows the reconstruction of data as it was valid at any point in the past. In other words, the data status that existed at a certain point in time, e.g. when a report was executed, can be queried. Historization also makes it possible to analyse the complete historical development of individual data records.
To meet these requirements, all data is subject to strict bi-temporal, two-dimensional historization. There is a functional and a technical validity period for each data set. The functional period results from the functional requirements, while the technical period reflects the time of storage. Another benefit of this type of historization is that it enables a logical restore on table level as explained in section 4.5.
¶ 1.4 Fine-Granular Security
Security is a central component: Personalised user accounts receive access rights on object, row and column level.
- On the first level, classic access rights are granted to groups of objects.
- On the second level, it can be decided for each object on the row level which data should be visible for which users.
- On the third level, sensitive columns and the respective user access can be defined. The declarative assignment of permissions ensures that this high level of detail remains maintainable. Administration is kept to a minimum as automated processes take over complex activities in the background.
The business department has access via virtual layers (view layers), which are placed on top of the data tables. The business department does not have direct access to the base tables. The view layer also maps the access security at object, row and column level.
¶ 1.5 Summary
Central features are:
- Shortest project lead time and easy handling in operation
- Highly parallelised, asynchronous loading without the need to define jobs
- Complete historization of data - traceability of all data changes
- Fine-granular authorisation concept with personalised access
- Use of existing well-known data structures without adaptation
- High performance queries
¶ 2 Architecture
The framework consists of 4 different modules, namely Automation, Core, Security and GDPR.
Each of those will be explained in more detail in the chapters 3 to 6. However, first the data flow, the structure and the loading process will be discussed.
¶ 2.1 Data Flow
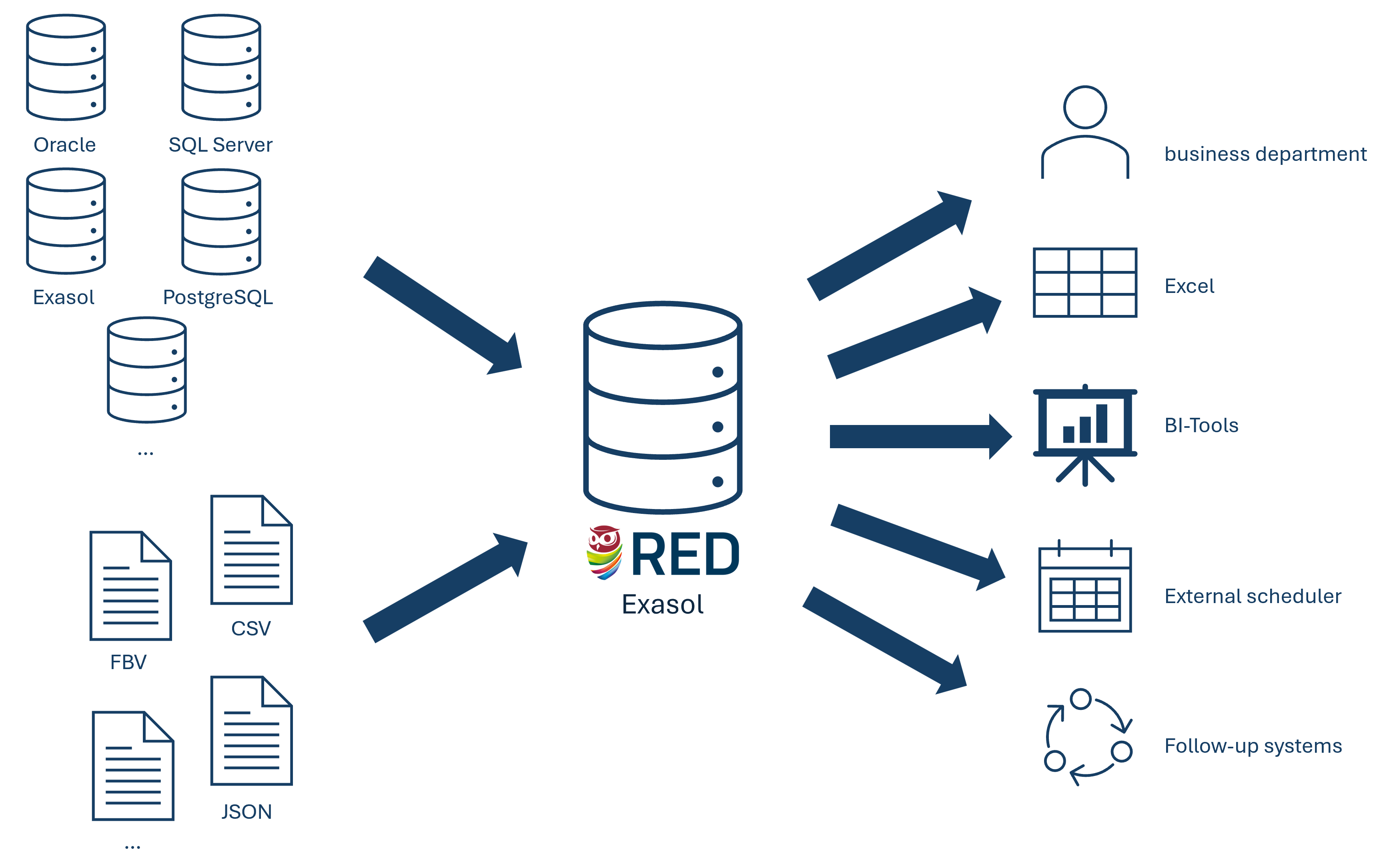
In principle, data is loaded from source systems into an analytical database. The data is loaded largely unchanged and historization information is added. A few transformations, such as the conversion of date values, can be performed before the data is persisted.
The framework can load data from multiple different sources. A connector is configured for each type of source (e.g. database, files, REST APIs, … - see Figure 1). The loading of the data and the historization are triggered in near real time, such that the business department is able to make decisions based on live data. Access for reporting by the business department or follow-up systems is secured by a view layer (see section 2.2).
¶ 2.2 Layered Structure
The framework consists of a layered structure (see Figure 2) that is divided into a reporting and a technical layer. The former allows for a secured access by reporting users, the latter is internal and not accessible to users.
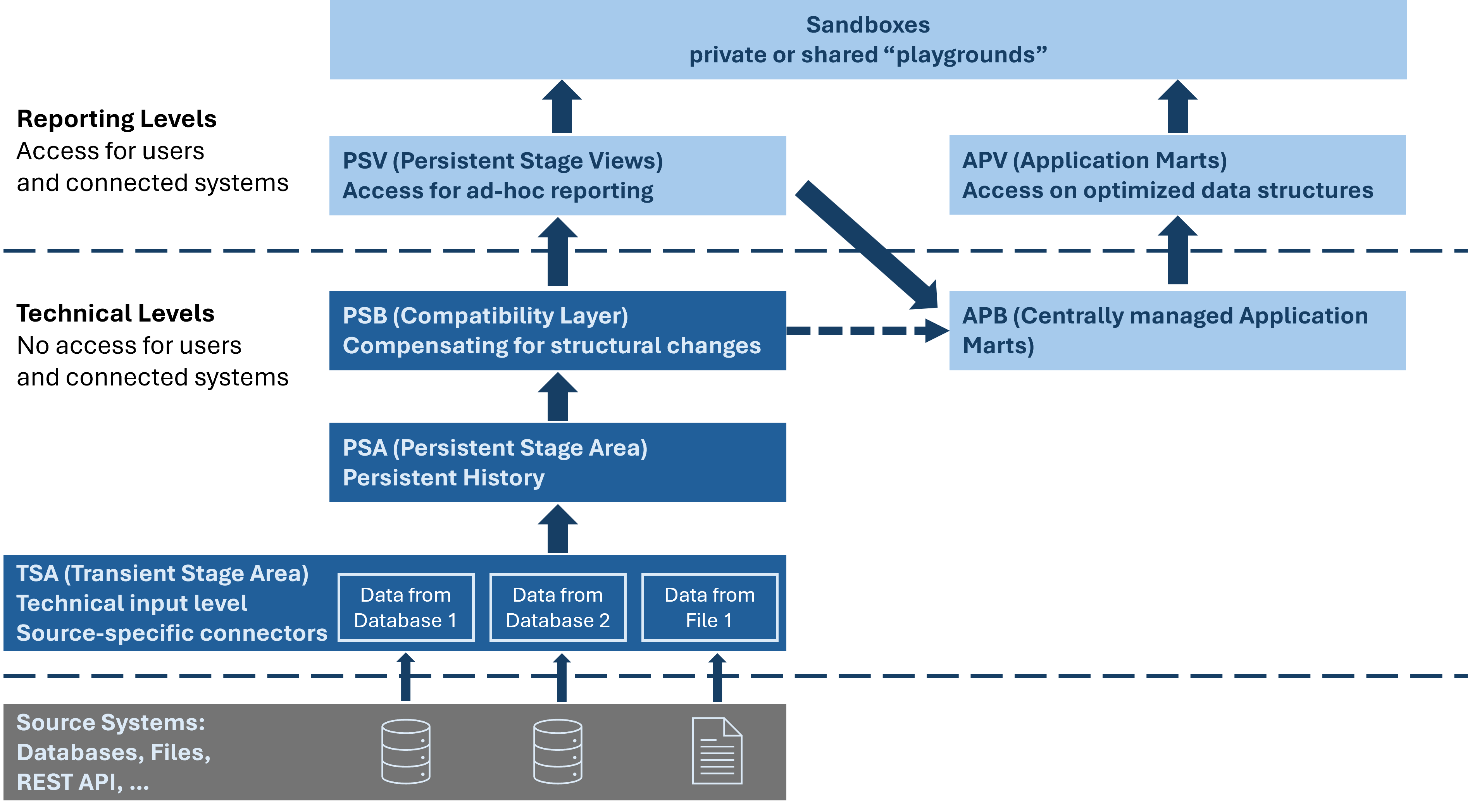
¶ 2.2.1 Reporting Layer
The reporting layer is fully secured and serves as the only way users can get access to data.
¶ 2.2.1.1 Persistent Stage Views (PSV)
This layer manages access to ad-hoc reporting via automatically generated views. The personalised access rights (row and column level security) are applied in the views of the PSV layer. For that reason, users will only see the data that corresponds to their individual rights.
The PSV layer is based on the PSB layer.
¶ 2.2.1.2 Application Marts (APV)
This layer manages access to centrally managed application marts via automatically generated views. Access rights can be assigned selectively and are independent of the access rights of the PSV layer. The APV layer is based on the APB layer.
¶ 2.2.2 Technical Layer
The technical layer holds the persisted data and is not visible to users.
¶ 2.2.2.1 Centrally Managed Application Marts (APB)
Centrally managed application marts are schemas that enable the persistence of complex queries and business models (e.g. data modelling as a star schema). They usually consist of views, but the top layer can also be materialised for performance reasons, e.g. for self-service BI tools when a response within milliseconds is necessary. The APB layer is directly based on the views of the PSB layer.
¶ 2.2.2.2 Persistent Stage Base (PSB)
This layer is a compatibility view layer to compensate for any structural changes in the layers below. Due to this layer a constant PSV layer is presented to the business department no matter what changes appear in the source systems. It consists of DR (dual date range) and TA (technically active) views. DR views show historization in both time dimensions (business date and technical date), whereas TA views only show technically active data.
The PSB layer is based on the PSA layer. The business attributes of the source tables are displayed 1:1. In addition, renaming or hiding a column and pre-calculations for data enrichment can take place in this layer.
¶ 2.2.2.3 Persistent Stage Area (PSA)
The PSA is the layer that serves as the data safe. In this layer the target tables with the historicized and persisted data, the technical tables and the views for the loading process are located. Additionally, to the data table, objects with the following postfixes might exist:
Tables:
- ERR: Error table for invalid rows
- CTL: Control table for historization process
- HT: Hub table for resolved dependencies
- LT#: Lookup tables for space reduction as will be explained in section 4.6
Views:
- DV: Difference view to detect new, changed and deleted rows
- PV: Point-in-time view to set BDATE and TDATE
- PV2: Point-in-time view 2 to inherit historization from the source
- HV: Hub view to populate a corresponding hub table
- CV: Correction view for missing references in the BSK calculation
- CVR: Correction view for missing references in data columns
- DEL: Deletion view for space reduction as will be explained in section 4.7
- FV: Fusion view for mapping inside the BSK calculation
- LV#: Lookup view to populate the corresponding lookup table
A postfix in this case means <TABLE_NAME>_POSTFIX.
In case of time dependencies between two or more tables, the framework automatically ensures that the tables are loaded in the appropriate order.
¶ 2.2.2.4 Transient Stage Area (TSA)
Every connector (see section 4.9) loads its data to this temporary stage without any modification. Once the data has been persisted in the PSA, the TSA data will be deleted after an adjustable number of days.
¶ 2.3 Loading Process
Starting from the source, the data is loaded into the TSA table. The DV view identifies new, changed and deleted rows that are permanently written into the PSA tables. Faulty data records end up in the ERR table. The PV view manages BDATE and TDATE time slices. Other views mentioned in section 2.2.2.3 might exist depending on the properties of the source objects.
Database objects whose name begins with "ADM_" contain information for batch control. This level is independent of the data structures loaded and is used to generally manage the system processes (e.g. frequency of execution of jobs or retention periods of log data).
¶ 3 Automation Module
The automation module includes control logic located on an external batch server in combination with technical views and tables inside the database. Logging, transaction and general utilities are included in this package as well. This module is an integral part of the core logic and mandatory for every other module.
RED-PSS is part of this module.
¶ 3.1 Process Control and Monitoring
Since the Exasol database comes without a scheduling mechanism, regularly running jobs are triggered by a separate batch server. The control logic, which is written in Python, is therefore shifted to an external Linux server. The batch server is connected to the database via a technical user that is used to log on to the database and has impersonate rights on other technical users.
Several technical tables (ADM_JOBS, ADM_WATCHER, LOG_MESSAGES, …) and the metadata for the data tables are located inside the database. Job and watcher definitions as well as queues for new loading processes are continuously checked and executed as soon as something shows up. The jobs themselves run as scripts in the database. Another of these automated tasks is the deletion of intermediate data and old log entries that are no longer needed.
All control and status information is located in views and tables in the database. Database objects whose name begins with "STA_" contain condensed overview information about the status and configuration of the system. Some objects hold ALERT and ALERT_REASON columns that indicate whether there is an immediate need for action. The information is prepared for usage in external monitoring tools or direct user queries. The alert levels and their meaning are:
- 0…OK
- 1…Warning
- 2…Error
Furthermore the ALERT_REASON column might show a textual description, if a warning or an error occured.
Views starting with "STA_" are always granted to public, while all other views and tables are only granted to the application manager.
Some of these "STA_" views are explained in more detail in the Monitoring Guide reachable via the following links:
¶ 3.2 Deployment
Software updates are versioned and distributed via GIT. If an update has been developed, successfully tested and released, an upgrade package with the corresponding version number can be pulled to the batch server (if connected to the internet) and installed. The installation is performed by an install tool that is also part of the automation module.
There are two different types of packages:
- Technical Version (TV): An automatically created install script installs changes in the core process.
- Business Version (BV): By just pressing a button, customer-specific changes (e.g. new tables from new sources, changes in existing tables) made exclusively via API calls generate the necessary CREATE, ALTER, … statements that are applied to the database. Furthermore, an export tool that automatically exports changes to GIT is also part of this module and located on the batch server.
The version history (TV & BV) can be seen in the ADM_VERSION_HISTORY view.
¶ 3.2.1 Transaction Brackets
Database objects such as scripts are typically run in the security domain of the definer of that object. However, sometimes other users need to have the right to invoke those objects, if granted based on their roles. Therefore, we created an API_DR script, which, based on ones permissions for specific objects, impersonates the definer to run these scripts. However, when running such API-scripts, that need to impersonate another user, one has to login as that user for each call and logout after each call again, making it impossible to run several calls within one transaction. Therefore we invented transaction brackets, which span across multiple calls.
IMPORTANT: Only users which possess their own schema can use transaction brackets!
¶ 3.2.1.1 How do these Transaction Brackets work?
When using transaction brackets one does not immediately run the scripts, but rather a table is created with all calls, which should be run as a different user. Only when all calls have been added and commited, does the process impersonate the other user and run all calls as that user. Afterwards the table is being deleted again.
IMPORTANT: If the steps that will fill the table with the necessary calls in the correct order of execution result in an error, one has to use API_REDSYS.TRX_ABORT as otherwise the calls that did not result in an error will stay in the table and when the transaction is started again, double entries might occur, resulting in more errors. One can also check which calls have been added to the table by switching to ones own schema and opening the table starting with '$TRX_'.
¶ 3.2.1.2 How to use Transaction Brackets?
To use transaction brackets one has to start a transaction by issuing the following command:
EXECUTE SCRIPT API_REDSYS.TRX_BEGIN();
As soon as the transaction is started, one can add objects, which should be run within the transaction, by typing in and executing the calls in the correct order. This will not result in the actual execution of these calls, but rather in those calls being added to the transaction table. Only after issuing the following command will these calls be actually executed:
EXECUTE SCRIPT API_REDSYS.TRX_COMMIT();
If an error occurs while running this transaction, the whole transaction will be aborted, the table will be removed and one has to define the transaction again.
If the transaction runs through without any problems, all calls have been successfully run impersonating the other user and the table containing the list of calls has been deleted.
¶ 4 Core Module
The core module combines the data import with different connectors with bitemporal & two-dimensional historization and calendar logic that leads to an object and application status which can be used to trigger applications.
¶ 4.1 Historization
A strict bitemporal, two-dimensional historization is used for all data, in order to be able to reconstruct all data changes. A given record has a period of functional and a period of technical validity. The functional validity results from the functional requirements, for example between which two dates a given interest rate applies and is referred to as the business date or booking date. The technical validity reflects the time of storage and the date upon which a further record is stored to replace it. This technical time dimension is referred to as loading date or technical date. The details behind the historization process will be described shortly.
Each table in the PSA layer has two sets of columns to describe the functional and technical validity of a record. The columns "BDATE_FROM" and "BDATE_TO" describe the functional validity and the columns "TDATE_FROM" and "TDATE_TO" describe the technical validity. The DR views in the PSV layer include both types of validity for each record. The Business Date is stored with calendar day accuracy, the Technical Date as a time accurate to milliseconds.
Two types of tables exist: Type-2 and Type-3. Type-2 corresponds to the definition of an SCD (Slowly Changing Dimension) Type-2. Type-3 tables are intended for event tables, where an event occurs on a particular date (BDATE instead of BDATE_FROM & BDATE_TO).
Type-2 is mostly used for all kinds of master data with bitemporal historization. The functional validity is given with the BDATE_FROM and BDATE_TO values, while the technical validity of a record is given with the TDATE_%. When a change is made to a record which applies to a given functional period, this change is noted in the TDATE_% columns.
Type-3 tables contain data related to a particular day, such as sales, which occur on a certain day. Type-3 tables can also be called "event tables". These tables only have a single BDATE column, which describes the date on which the event occurred. The historization is therefore technically unitemporal. On the technical level however, historization is still bitemporal.
SCD Type-1 tables, which are marked by neither a bitemporal historization or a single point in time, do not exist in the framework as they contradict the idea of bitemporal historization. Type-1 tables do not fulfil the basic condition of strict traceability as existing values in these tables are simply overwritten.
Internally there are optional "%_HT" tables in the PSA layer that are managed as Type-0. They contain the relation of the business surrogate key (BSK) to the business key.
¶ 4.1.1 Identification of Records via the Business Surrogate Key (BSK)
The Business Surrogate Key (BSK) serves as the basis and absolute prerequisite for the historization logic as each data record can be uniquely identified via the BSK.
This means that the data record, and all historical variants of this data record that existed before it, have the same BSK. A query via the BSK therefore returns all records from which the currently valid record has developed from, showcasing the complete temporal history.
This means any changes to a data record, for example made by SQL UPDATES in the source system, are traceable via the BSK. This also allows for the reconstruction of a record as it was at any point in the past. Furthermore, the complete historical development of individual records can be analysed.
¶ 4.1.2 Definition of the Business Surrogate Key (BSK)
The Business Surrogate Key (BSK) is composed of the domain (e.g. "SubCompany1") and the business key (logical key). The business key (logical key) depends on the table type and is made up of values from at least one column in the source tables. Which columns can be used as a business key may have to be defined together with the end users as this key has to be unique for each entry in the table and therefore sometimes one column containing unique values is sufficient for becoming the logical key, other times several column values have to be combined to produce a unique identifier for each entry.
A hash value (MD5) is calculated using the columns of the business key and the domain and stored in addition to the business key columns.
Technically, the composition of the BSK can be seen in the definition of the "%_DV" view of the respective table. In the "%_DV" views, the hash value is calculated via the BSK, stored in the PSA tables and finally made available in the PSV views in the "BSK" column. In addition to historization, this column serves exclusively as a join attribute and should not be used as a filter criterion. Due to technical reasons, the content of the BSK fields may change in the future. The columns used to create the BSK are available in the PSV views as possible filter criteria.
¶ 4.1.3 Process of Historisation
Updating of the records is done by comparing the content of each record in the source system with the content of the already existing record. If there is no change, it is not stored again.
If a business attribute of a record changes, the old record is closed with BDATE_TO = "yesterday" and a new record is created with BDATE_FROM = "today". If a record is physically deleted or marked as deleted in the source system (e.g. a "deleted flag" is set), then the "BDATE_TO" column is set to this day and thus the business validity of the record is terminated. In addition, a new record with infinite validity is created with the ACTIVE column set to 'false'. This gives the option to display deleted records if this is explicitly required.
If the same data record (identical BSK) with the same BDATE_FROM is delivered again during a reload of the data, but there has been a change to an attribute, then several business-valid records exist at one point in time. In this case, the history of the change of the data can be traced with the help of the Technical Date ("%TDATE%" columns). The old record is closed with TDATE_TO = "Load time minus 1 millisecond" and the new record is inserted with TDATE_FROM = "Load time". In the case of a Type-3 table, this can be explained in a simplified way: A sale was booked on 01.12.2020. Subsequently, the amount is changed because an incorrect value was inserted. The business date (BDATE) does not change as a result, so the historization is achieved via the TDATE.
The form of historization described before is called standard historization throughout the rest of this document.
If it is necessary to trace the time of a data change, an extended form of historization must be used, which will be called "strong" historization for the rest of this guide. An explanation of this form of historization can be found in section 4.1.3.3.
Historization prevents overlapping time slices (time periods) in data records. If overlapping time slices occur, they are automatically corrected. In addition, as is generally the case in data warehouses (DWHs), a record is never physically deleted.
¶ 4.1.3.1 Standard Historization
If a record is corrected in the source system, but the Business Date remains the same, then the previous record is technically closed. This means that the column "TDATE_TO" is set to 1 millisecond before the loading time and the column "TDATE_FROM" in the new record is set to the loading time. There are then two records with the same functional validity period according to BDATE, but only the newer record is also valid in regard to TDATE, i.e. not terminated.
"Not terminated" means the date is set to "9999-12-31", i.e. infinite from a business perspective.
If the Business Date is also changed when a record is modified, then a new record is created with these changes. The day on which the change is to take effect is entered in the column "BDATE_FROM". In the old data set, the column "BDATE_TO" is set to the day before this date. In this case the TDATE columns remain unchanged.
¶ 4.1.3.2 Changes to a record using standard historization
The following shows the evolution of an actual record as it is changed using standard historization.
The "%DATE%" columns of the view and a business attribute (“Bezeichnung”) of the BSK are queried after each change using the following SQL statement:
SELECT
bdate_from,
bdate_to,
tdate_from,
tdate_to,
bezeichnung
FROM redpsv_db1_dr.table1
WHERE bsk='1c63ce7fbfc874f72ea480d4682344a1'
ORDER BY bdate_from;
First a new record is loaded on the 30th of December 2019 (TDATE_FROM). This record is given infinite validity from both a business and technical perspective, resulting in the %DATE_TO columns being set to 31.12.9999. This new record can be seen in figure 4.
| bdate_from | bdate_to | tdate_from | tdate_to | Bezeichnung |
|---|---|---|---|---|
| 2019-12-01 | 9999-12-31 | 2019-12-30 17:50:15 | 9999-12-31 00:00:00 | 25 GRILLPARZER |
The business attribute “BEZEICHNUNG” is being changed from “25 GRILLPARZER” to “100 JAHRE SALBURG FESTSP” on January 3rd, 2020. This results in the functional validity of the record being terminated, meaning BDATE_TO is being set to the day before the change, namely January 2nd, 2020. At the same time a new record with the new value for “BEZEICHNUNG” is added. The record is functionally valid starting from the change until infinity. This means the BDATE_FROM is set to the date of the change, namely the 3rd of January 2020 and the BDATE_TO value is set to 31.12.9999. As the record is only loaded a day afterwards, the TDATE_FROM is set to the 4th of January 2020 and as the technical validity is also infinite the TDATE_TO value is also set to 31.12.9999. The query shown above, now returns the entries shown in figure 5.
| bdate_from | bdate_to | tdate_from | tdate_to | Bezeichnung |
|---|---|---|---|---|
| 2019-12-01 | 2020-01-02 | 2019-12-30 17:50:15 | 9999-12-31 00:00:00 | 25 GRILLPARZER |
| 2020-01-03 | 9999-12-31 | 2020-01-04 04:48:13 | 9999-12-31 00:00:00 | 100 JAHRE SALZBURG FESTSP |
Changing the business attribute "BEZEICHNUNG" again leads to the termination of the second data record and the creation of a third. All three data records are technically valid on the current date, but only the new record also has functional validity as can be seen in figure 6.
| bdate_from | bdate_to | tdate_from | tdate_to | Bezeichnung |
|---|---|---|---|---|
| 2019-12-01 | 2020-01-02 | 2019-12-30 17:50:15 | 9999-12-31 00:00:00 | 25 GRILLPARZER |
| 2020-01-03 | 2020-01-15 | 2020-01-04 04:48:13 | 9999-12-31 00:00:00 | 100 JAHRE SALZBURG FESTSP |
| 2020-01-16 | 9999-12-31 | 2020-01-17 06:30:34 | 9999-12-31 00:00:00 | 20 EUR 100 J SALZB. FEST |
¶ 4.1.3.3 Strong Historization
If it is necessary to be able to trace the time of a data change, an extended form of historization must be used. "Strong historization" enables this traceability. In addition to the mechanisms described above, the previously valid record is copied and stored with unchanged valid BDATE_TO but terminated TDATE_TO values. TDATE_TO is set to the load time of the new record, which also records the time of the change. A second data record is inserted in which the column "BDATE_TO" is set to the time of the modification, i.e. the technical closure takes place. And finally, a third data record is inserted, which is both functionally and technically valid. This means that in this record the values of the columns "TDATE_TO" and "BDATE_TO" are in the future. Thus, changing a record in the source system creates two new records.
¶ 4.1.3.4 Changes to a record using strong historization
The following section shows an example of the development of the same record with the same data changes as was done in section 4.1.3.2 for standard historization.
The "%DATE%" columns of the view and a business attribute (“Bezeichnung”) of the BSK are queried after each change using the following SQL statement:
SELECT
bdate_from,
bdate_to,
to_char(tdate_from, 'YYYY-MM-DD HH24:MI:SS.FF3') tdate_from,
to_char(tdate_to, 'YYYY-MM-DD HH24:MI:SS.FF3') tdate_to,
bezeichnung
FROM redpsv_db1_dr.table1
WHERE bsk='1c63ce7fbfc874f72ea480d4682344a1'
ORDER BY bdate_from, tdate_from;
The TDATE columns are queried with an accuracy of 1 millisecond (ms).
First a new record is loaded on the 30th of December 2019 (TDATE_FROM). This record is given infinite validity from both a business and technical perspective, resulting in the %DATE_TO columns being set to 31.12.9999. This new record can be seen in figure 7.
| bdate_from | bdate_to | tdate_from | tdate_to | Bezeichnung |
|---|---|---|---|---|
| 2019-12-01 | 9999-12-31 | 2019-12-30 17:50:15.305 | 9999-12-31 00:00:00.000 | 25 GRILLPARZER |
The business attribute “BEZEICHNUNG” is being changed from “25 GRILLPARZER” to “100 JAHRE SALBURG FESTSP” on January 3rd, 2020. This creates two new data records.
- In order to be able to trace when this change took place, the old data record is copied and saved with unchanged BDATEs but terminated TDATE_TO (first line in figure 8). TDATE_TO is set to 1 millisecond before the loading time of the new record.
- The functional validity of the copied record is being terminated, meaning BDATE_TO is being set to the day before the change, namely January 2nd, 2020. As the record is only loaded a day afterwards and the technical validity of this record starts with the load time, the TDATE_FROM is set to the 4th of January 2020 and as the technical validity is infinite the TDATE_TO value is also set to 31.12.9999 (second line in figure 8)
- At the same time a new record with the new value for “BEZEICHNUNG” is added. The record is functionally valid starting from the change until infinity. This means the BDATE_FROM is set to the date of the change, namely the 3rd of January 2020 and the BDATE_TO value is set to 31.12.9999. As the record is only loaded a day afterwards, the TDATE_FROM is set to the 4th of January 2020 and as the technical validity is also infinite the TDATE_TO value is also set to 31.12.9999. This entry can be seen in line 3 in figure 8.
The query shown before, now returns the entries mentioned above shown in figure 8.
| bdate_from | bdate_to | tdate_from | tdate_to | Bezeichnung |
|---|---|---|---|---|
| 2019-12-01 | 9999-12-31 | 2019-12-30 17:50:15.305 | 2020-01-04 04:48:13.895 | 25 GRILLPARZER |
| 2019-12-01 | 2020-01-02 | 2020-01-04 04:48:13.896 | 9999-12-31 00:00:00.000 | 25 GRILLPARZER |
| 2020-01-03 | 9999-12-31 | 2020-01-04 04:48:13.896 | 9999-12-31 00:00:00.000 | 100 JAHRE SALZBURG FESTSP |
Changing the business attribute "BEZEICHNUNG" again adds two records:
- In order to be able to trace when this change took place, the old data record is saved again with unchanged BDATEs but terminated TDATE_TO (third line in figure 9). TDATE_TO is set to 1 millisecond before the loading time of the new record.
- The formerly newest entry (third line in figure 9) is copied and functionally terminated, by setting the BDATE_TO to the day before the change, in this case the 15th of January 2020. The technical validity begins again with the loading time, in this case a day after the change, namely the 17th of January 2020 and therefore the TDATE_FROM value is set to that date. As the entry is technically infinitely valid, this results in the TDATE_TO value to be set to 31.12.9999 (fourth line in figure 9).
- A new data record with the new value of “BEZEICHNUNG” is added, which is functionally valid from the day of the change to infinity, resulting in the BDATE_FROM value to be set to the day of the change, in this case the 16th of January 2020 and the BDATE_TO value to be set to 31.12.9999. The record is loaded a day after the change and also has a technical infinite validity, resulting in the TDATE_FROM value to be set to the 17th of January and the TDATE_TO value being set to 31.12.9999 as well.
Therefore, three data records exist, containing the original value of “BEZEICHNUNG” and each change to this value, which are technically still valid on the current date, but only the newest record also has functional validity. These entries as well as the entries necessary to be able to trace changes can be seen in figure 9.
| bdate_from | bdate_to | tdate_from | tdate_to | Bezeichnung |
|---|---|---|---|---|
| 2019-12-01 | 9999-12-31 | 2019-12-30 17:50:15.305 | 2020-01-04 04:48:13.895 | 25 GRILLPARZER |
| 2019-12-01 | 2020-01-02 | 2020-01-04 04:48:13.896 | 9999-12-31 00:00:00.000 | 25 GRILLPARZER |
| 2020-01-03 | 9999-12-31 | 2020-01-04 04:48:13.896 | 2020-01-17 06:30:34.677 | 100 JAHRE SALZBURG FESTSP |
| 2020-01-03 | 2020-01-15 | 2020-01-17 06:30:34.678 | 9999-12-31 00:00:00.000 | 100 JAHRE SALZBURG FESTSP |
| 2020-01-16 | 9999-12-31 | 2020-01-17 06:30:34.678 | 9999-12-31 00:00:00.000 | 20 EUR 100 J SALZB. FEST |
¶ 4.1.3.5 Several changes on the same business date
If a record is changed on the same business date (BDATE) this is called a change in an “old booking”. Such a change is therefore only represented via the technical dates.
The original record is technically closed, by setting the TDATE_TO to 1 millisecond before the loading time of the new record, as can be seen in figure 10 in the red markings. This means that only one of the displayed entries is technically valid, but this ensures that the historical development of the data can be traced.
| bdate_from | bdate_to | tdate_from | tdate_to | Bezeichnung |
|---|---|---|---|---|
| 2019-12-01 | 2020-01-02 | 2019-12-30 17:50:15.305 | 9999-12-31 00:00:00.000 | 25 GRILLPARZER |
| 2020-01-03 | 2020-01-15 | 2020-01-04 04:48:13.896 | 9999-12-31 00:00:00.000 | 100 JAHRE SALZBURG FESTSP |
| 2020-01-16 | 9999-12-31 | 2020-01-17 06:30:34.678 | 2020-03-15 11:46:30.339 | 20 EUR 100 J SALZB. FEST |
| 2020-01-16 | 9999-12-31 | 2020-03-15 11:46:30.340 | 9999-12-31 00:00:00.000 | 20 EUR 100 J SALZBURG FESTSP |
¶ 4.1.3.6 Historization of deleted data
It is possible to also historize the deletion of records in the source system. This can either be done by introducing an delete flag or by performing a full load and comparing the PSA with the source data.
There are two possibilities of how to process deletions, depending on the needs of the business department. Either by terminating the BDATE or the TDATE validity.
Furthermore, deleted records can be saved, by introducing an ACTIVE flag. This feature might be helpful to e.g. get deletion statistics.
¶ 4.2 PSA Repository
The repository resides in the REPPSA schema and allows for the automatic generation of PSA tables.
After LOADER and LOADER_BD have been defined for the CFI or DBI Connector, and TSA tables have been created using the S_CFI_CREATE_TSA_TABLES or S_DBI_CREATE_TSA_TABLES APIs, metadata for the PSA layer can be created in the REPPSA schema using the S_ADD_OBJECT API.
This API creates metadata for a specified table and saves that data in the following main tables:
- REP_TSA_OBJECTS: metadata for TSA objects. This contains, amongst other things, the schema and table name in the TSA layer, business release version, business domain, and an expression that describes how the business date is to be assigned when loading data.
- REP_TSA_COLUMNS: metadata for TSA columns. This contains, amongst other things, the column name and data type, whether the column contains the business date, the position of the column in the identity column (IDC), the position of the column in the business key (BK) – logical key, the position of the column in the business surrogate key (BSK), information over whether the column is a reference column to another table and column visibility in the PSB layer. IDC and BK are relevant only for so-called %_HT Tables.
- REP_PSA_OBJECTS: metadata for PSA objects. This contains, amongst other things, the schema and table name in the PSA layer, the business release version, table type (SCD_TYPE), historization type, and information on how deleted records are to be treated.
- REP_PSA_COLUMNS: metadata for PSA columns. This contains, amongst other things, the column name and whether the data in the column is used to mark the end of the functional validity of a record (BDATE_TO).
- REP_PSA_TSA_OBJECTS: metadata to link PSA and TSA objects
- REP_PSA_TSA_COLUMNS: metadata to link PSA and TSA columns
The metadata is completely managed by API scripts.
The API call S_REPPSA_COMPILE automatically creates all necessary PSA tables and views, based on the above-mentioned metadata. In the case of changes to the table structure, an ALTER TABLE statement is generated and executed automatically.
¶ 4.3 Calendar Logic
A complete calendar solution to steer the loading of data is also offered.
For each source table it is necessary to describe at which point the source system is ready to provide the data and therefore when the data should be loaded. With the calendar logic, it’s possible to define an individual load cycle for each object, considering business days, weekends, holidays, month and year ends etc. It’s also possible to introduce a delivery offset if the source provides data with a delay. It is, of course, also possible to define dependencies between loads, so that certain data is only loaded once other data is available.
These options are necessary due to some data being loaded every day, seven days a week, other data is only available on business days, which may vary, dependent upon national holidays. Other data is only available on the last day of the month, where that day is a business day. If the last day of the month is not a business day, it will be loaded on the first business day after the last day of the month. Some data is not ready at midnight, when the load would automatically begin. In this case the load can only begin at a time when the data is available.
¶ 4.4 Object and Application Status
The framework tracks the entire load process, which results in a load status information on object level for every object and every BDATE. This status can be seen in the "STA_OBJECT_STATUS" view, where the status of each PSA-table per BDATE and BDOMAIN contained. An overview of the most important statuses is shown below:
- FINISHED: The object has been loaded and the day is over. All loads for this BDATE are completed.
- LOADED: The object has been loaded and the day is not yet over. The last load was successful, but more loads for this BDATE may arrive.
- PSA_WAITING: The object is waiting for another table because of dependencies
- PSA_MISSING: The TSA load is already completed but the PSA-table is still not loaded
- TSA_WAITING: The delivery from the source system hasn’t yet arrived, but a delay is expected
- TSA_MISSING: The delivery from the source system hasn’t yet arrived, a delay is NOT expected
- ERROR/FAILED: There has been an issue during the load
LAST_PSA_FINISHED shows the timestamp of the last completed load for this very BDATE and BDOMAIN. If the status values TSA_MISSING or PSA_MISSING are reached, an alert value of greater than zero is caused.
Those object statuses can be combined into an application status of multiple objects.
¶ 4.4.1 Applications
Applications are logical combinations of database objects. An application consists of a name and the assigned database objects. Objects are added to an application via search rules.
An application serves as a unit, whose state can be queried. This state is the result of the states of each object belonging to an application. If, for example, the data of all objects of an application for a specific BDATE was loaded and historized successfully, the application state for this BDATE and application is ‘FINISHED’.
Furthermore, actions can be associated with applications, which will be executed if a specific state is reached.
There are three different state columns in the view REDADM. RED_APP_STATUS, which each can have the status 'FINISHED’ or ‘UNFINISHED’:
- LOADED_STATUS: the state switches to ‘FINISHED’ as soon as all tables belonging to the application have reached either the status ‘LOADED’, 'FINISHED' or 'TSA_WAITING' for the BDATE. This means that the status becomes 'FINISHED' each time as soon as all components have reached the status LOADED except for those which are not yet expected for delivery according to the underlying load cycle. This column switches to ‘FINISHED’ before the other two columns.
- PRELIM_STATUS: this column switches to ‘FINISHED’ when all tables on a calendar day have been successfully loaded. For the BDATE, which has been loaded for that day, data of a few, defined tables can still be missing and be delivered a few days later. An example therefore would be month-ultimos, to which the data of some of the tables will only be delivered a few days afterwards. To be able to detect such tables of a BDATE which might not be “delivered”, the information for the calendar information such as the “Load-Cycles” of a BDATE is being used. If no more data on a calendar day is expected, due to that information, the column PRELIM_STATUS is set to ‘FINISHED’.
- FINAL_STATUS: If the loading of all tables of a BDATE has been successfully completed, this status switches to ‘FINISHED’. This also includes data for tables which has not been delivered on an earlier BDATE, as has been explained in the PRELIM_STATUS column before. This column switches to ‘FINISHED’ as the last one.
The FINAL_STATUS (as well as the PRELIM_STATUS) switches back to 'UNFINISHED' if at least one component of this very application is reloaded. After successful load it again reaches the 'FINISHED' status (presuming that all other components are 'FINISHED' as well at this point in time). The same is true for the LOADED_STATUS apart from the fact that the individual object status needs only to be 'LOADED'.
¶ 4.4.2 Actions
There are five different kinds of actions.
- MAIL: Notification per mail, for example after a successful load of the data of a BDATE
- EXP_MAIL: Notification per mail, but with an attachment, for example a csv file containing the views of the tables, which are part of the application
- EXP_SFTP: Transfer of data per SFTP
- JEXEC: Execute an external Job, such as Control-M
- MAT: Materialize tables and views, due to performance reasons
¶ 4.5 Logical Restore on Table Level
Another advantage of the bitemporal and two-dimensional historization is the ability to perform a logical restore on table level without having to restore the whole database, which might take hours. Just by picking a single or a set of tables and defining a point in time to which the tables should be reset, the original state will be restored. Data will be deleted, and metadata flagged as deleted. Even a new import of data can be triggered in this process.
¶ 4.6 Space Reduction
For every change to a record in a historicised table, at least one new record, containing the complete contents of that record, plus any changes, will be created. For tables with large records this can lead to a rapid increase in the space required to store the data. In most cases, however, only a small number of columns within a record are actually changing. A large number of columns within a record generally remain unchanged, or only change infrequently.
In the PSA repository it’s possible to configure a given PSA table to use Space Reduction. In such a case the data in the PSA table is split between rapidly changing and largely static data. Upon a change to one of the rapidly changing columns, only the set of rapidly changing columns will be historicised. The set of slowly changing columns remains untouched. This reduces the space required to store these changes. Space Reduction therefore reduces the amount of space needed to store the entire data in a PSA table.
For the end user it is completely hidden whether “Space Reduction” is used or not. The process is also completely and automatically reversible, with no loss in data.
¶ 4.7 Delete Logic
Over time the amount of data stored within a data warehouse will inevitably grow. However, most likely not all the data will need to be retained indefinitely. Some data might only need to be retained for a few months, other data might need, for regulatory reasons, to be retained for a number of years.
Within the framework it’s possible to define erase groups for deleting PSA data. The data in the TSA layer is only retained for a matter of days. Each group can be defined at the table, schema or BDOMAIN level, or a combination of all three. Within each group an include and exclude regular expression can be created at table, schema or BDOMAIN level to define the objects handled by, or ignored by, this group.
Each group has a retention period, which defines for how long the data in this group should be retained. Some data within a table, for example data created at month end, may need to be held for longer. For this data a special calendar can be created to specify these dates. (see section 4.3). For the data linked to such a calendar a special retention period can be defined.
If a PSA table is not covered by an erase group, then the data within that table will not be deleted.
A protocol of the delete process is written to the database, including how many records from which tables were deleted, and with which load run the deleted data were loaded into the DWH.
¶ 4.8 Data Lineage
The existing PSA_OBJ_LINEAGE table lineage view allows for tracking the origin and paths of data in a database. This feature is particularly useful for data management and compliance. With the upcoming module, the functionality is extended to also support column lineage. This enables companies to track in even more detail how individual data fields in tables are created and transformed. This is crucial for data accuracy and quality.
Additionally, an external governance tool can be integrated into the system to optimize data management and tracking, ensuring that all compliance requirements are met. This enables more efficient and transparent data management within businesses.
¶ 4.9 Connectors
Each type of external data source is connected with a specific connector that is used to load data into an analytical database (e.g. Exasol). Currently two connectors are included in the module, one for databases and one for files.
¶ 4.9.1 Database Interface Connector
The generic DBI-Connector is used to access any database via JDBC or using custom connectors provided by Exasol.
Special features are supported for the following databases:
- Exasol
- Oracle
- Microsoft
- Postgres
A Change Data Capture (CDC) mechanism is used to regularly check the data in the source system.
Any changes can then be immediately spotted.
An interface with a REST API can also be used to fetch data. The REST API calls, wrapped in a view, serve as a source for the DBI Connector.
¶ 4.9.1.1 Process
"Watcher" processes check at regular, configurable, intervals whether any data has been changed in the source system. The configuration of these processes is described in the next section. If a change is detected, an entry is made in table DBIADM.DBI_CDC_LOG, visible through view DBIADM.DBI_CDC_PENDING. The watcher then starts the loader process to extract the data from the source system and stores it in the TSA tables. Based on the loader settings, the extracted data is assigned to a business date (BDATE) and fed to the PSA load for further processing.
The CDC type (Change Data Capture) for each table is stored as a setting in the DBI_LOADER table, and can take one of the following values:
- FULL: the entire contents of the source table are read at each load, with the framework filtering any changes in the data for further processing.
- INCR: only changed data records are transferred, not the entire table. The method used to identify the changed records is configured in the DBI_LOADER table.
- CT: even though the title “Change Tracking” is borrowed from MS SQL Server it supports any type of near-real-time tracking of data changes in any of the supported databases. The Change Tracking method captures any changes in records and provides the primary keys of those changed records and the change operation used (insert, update, delete).
Generic statements for checking the status of a table, and detecting any changes in source tables, are defined in the table DBI_CT_GROUPS. This could be Change Tracking within MS SQL Server, a trigger framework, or some other method of tracking changes. In table DBI_LOADER_BD you define the CT_GROUP, and therefore the CT method, to be used for a given table. As soon as changes are detected, the changed records are loaded into the TSA layer. If for some reason it is not possible to use the CT method, for example if Change Tracking has temporarily been disabled on the source table, a fall-back mechanism guarantees either a full or incremental load, as defined in DBI_LOADER.
¶ 4.9.1.2 Configuration
Metadata stored in the DBIADM schema is used to configure the DBI Connector. Various APIs are used to manage this data.
The following is an overview of the configuration steps:
-
Table ADM_PARAMS contains the settings for parallelisation and logging.
-
Table ADM_JOBS contains the control data for regularly running jobs.
-
Tables DBI_CDCG_WATCH and DBI_CDCG_WATCH_BD define when a load process should start for a group of source tables, and where the tables are to be found.
-
Table DBI_CDCG_WATCH defines where the trigger for starting the load is to be found and what it looks like. The status of this trigger is regularly queried, and the result is stored in table DBI_CDCG_WATCH_STATUS. This "watcher" process is started as a job from the batch server. The definition of the job is stored in table ADM_JOBS. If the next status query discovers changes to be loaded, a new load process for the group of tables is started through an entry in table DBIADM.DBI_CDC_LOG.
-
Table DBI_CDCG_WATCH_BD is used for the optional division of the data into different business domains (BDOMAINs).
-
The three DBI_LOADER% tables are used to store information about the source table:
- Table DBI_LOADER contains a list of tables that are to be loaded together, i.e. for which there is a common trigger for loading. These tables are assigned to a common CDC_GROUP.
- Table DBI_LOADER_BD defines for each source table for which BDOMAINs data should be loaded. This table also defines where the source table is to be found and into which TSA table it is to be loaded.
- Table DBI_LOADER_COLUMNS specifies those columns in the source system with a time data type with a precision higher than 1 millisecond. Exasol can only store time data with a maximum precision of 1 millisecond, so the data in these columns must be converted to VARCHAR before being read from the source system.
¶ 4.9.2 Common File Interface Connector
The CFI-Connector is used to load and historize CSV, FBV and JSON files. The mode of operation is very similar to the DBI-Connector, but currently only a FULL load is supported. For PSA tables of Type-2 (master data tables) this is the entire contents of the table, for PSA tables of Type-3 (event tables) it contains the current daily changes or those of several days.
JSON files will be prepared and made visible in the database via a view. It’s possible to decide whether only certain key value pairs will be displayed, or the entire buffer. The data in this view will then be loaded via the DBI connector.
The files can contain data for one or more business days, whereby the classification is made by the following logic (with descending priority):
- BDATE is in the rows of the data records
- BDATE is in the file name
- Today's date is used, yesterday's date is used for the initial load.
¶ 4.9.2.1 Process
The following directories are located on the batch server of the respective load environment (DEV, TST, PROD):
- data/input (delivery)
- data/work (processing)
- data/error (not successfully loaded)
- data/archive (successfully loaded)
CSV or FBV files are loaded into the input directory and provided with the temporary extension ".tra" or ".TRA".
Upon successful delivery, the delivering process must remove this extension. From this point on, the delivery is considered finished and successful. ".tra" (whether upper or lower case) files will not processed. This prevents the import of incomplete files in the event of a process termination.
A watcher view looks at the input directory and displays the files contained there (except ".tra"). If new files are detected, a prepare process moves them to the work directory. A unique run ID is then assigned. The control process then carries out the loading process. If the loading is successful, the file is moved to the archive directory, otherwise to the error directory.
Behaviour in Case of Error:
- Error due to network termination or system-related: completely normal restart logic as with DBI- watcher
- Load is completed, but some rows could not be loaded due to format errors. This is called "rejected rows". There is a different procedure depending on the file type.
- FBV: The number of rejected rows must be 0 for a successful import, otherwise the load will be set to Error and the file will be moved to the error directory.
- CSV: The number of rejected rows can be configured via a parameter.
- If the number is above the limit, a reload will take place. This means that the file must be corrected manually and placed in the input directory again.
- If the number is below the limit but above 0, this is displayed in a warning, but the file is considered to have been loaded successfully and is moved to the archive directory.
¶ 4.9.3 Custom Specific Connector
Connector types are not limited to CFI and DBI connectors. Custom connectors of any type can be designed and developed if needed. It could be a customer specific connector, with specific logic and business rules, or an event streaming platform, such as Apache Kafka.
¶ 4.10 Testing
A testing tool can be provided for free as a part of the framework. The tool allows for the creation of test cases and workflows to evaluate any given functionality. These tests can then be automatically executed against any RDBMS from within a docker container.
Test workflows are easily configured as JSON files.
Test datasets – random or predefined - can easily be created at the beginning of a test workflow and then dropped at the end.
¶ 4.11 Data Patching
The aim is to allow data correction in the PSA layer, regardless of the daily load, with the same historization method used as per a normal load. It should also be possible to not only correct data within the PSA layer, but the process should be designed so openly that it is possible to manually correct and reload any data that have caused errors.
An example where this process would be necessary would be a technical error occurring when loading data from the TSA into the PSA. The problem record is written into an error table and can then be prepared for reloading by the patch framework, using the necessary API calls.
The loading of the changed data should be carried out using the existing load processes, from the TSA layer to the PSA layer. It is therefore not necessary to change the existing load logic.
The workflow in the patch framework is controlled by a number of API calls, both for defining and configuring a patch and for controlling the process itself.
¶ 4.11.1 Process
The patch definition is defined, specifying the PSA object to be corrected, the BDOMAIN, and an optional WHERE clause to restrict the process to only certain rows of data. APIs are used to create the patch definition in the patch metadata tables. The system automatically assigns a “PatchID” for further traceability.
Upon starting the patch process the corresponding objects and data for the selected “PatchID” are prepared. The objects are created in their own patch schema. Not only are the settings that are part of the patch definition (BDOMAIN and WHERE clause) applied, but it’s also ensured that only technically valid records are considered.
The data in the patch table is in the same structure as the original TSA table. This enables the same load process to be used as by a normal load into the PSA layer. By storing the data in the TSA layer, further loading, including the correct historization of any changes, can be carried out using the standard loading process.
¶ 4.12 Logical Metadata Backups (LBUs)
Many of the schemas have a view with the name 'LBU_RESTORE_COMMANDS'. This means that for this schema a kind of a "snapshot" does exist. This view kind of reverse engineers all 'ADD' operations, which are needed to get the exact same state of metadata for all tables within a schema if this schema would need to be recreated in an empty framework. This means by issuing all of the commands in the 'LBU_RESTORE_COMMANDS' view, in the order, as described in the IMPORTANT banner below, the exact same state can be recreated pretty easily.
IMPORTANT: As some 'ADD'-functions rely on other 'ADD'-functions being executed beforehand, one has to select the list of 'ADD'-functions from the 'LBU_RESTORE_COMMANDS' view using
order by order_colto fulfill those dependencies!
¶ 5 Security Module
This module includes object, row and column level security as well as sandboxing and the administration of users and privileges via APIs. Furthermore, the integration of an external identity management system, such as Active Directory belongs to this module. Metadata tables are filled with the respective settings and multiple refreshing jobs apply those settings periodically.
¶ 5.1 RED authorization concept
The access for issuing queries is only granted to personalized user-accounts. This allows for fine-granular allocation of rights and for informative auditing. Authentication and authorization are also managed via these accounts. The only exception from this personalization rule are batch user accounts (user type “Generic User – GU”), which do not possess any relation to a physical person.
In 3-Tier architectures the identity of the person is also forwarded to the database, as can be seen in section 5.2.
Access authorisations are assigned at object (see section 5.4), row (see section 5.5) and also at column level (see section 5.6).
Objects are combined into object groups, which can be assigned access rights (see section 5.4)
There are three different user account types in RED for accessing the PSV-layer (reporting layer):
- Human User (HU): personalized user accounts for physical persons
- Generic User (GU): user accounts which are not bound to any specific person, e.g. batch users
- Technical User (TU): user accounts for 3-tier architecture
Any user accounts not belonging to any of the beforementioned user account types is labelled as “unclassified user account”. The three beforementioned RED account types will be discussed in more detail in following paragraphs.
¶ 5.1.1 Human User (HU)
To gain access to the database, each physical person gets their own personalized database account. These account types are called human user (HU) in RED. A HU can also own a database schema, a so-called private sandbox (see section 5.7.1), which can be created either during the creation or a change of a user. The transfer of access rights on objects in these schemas to other user accounts is prohibited and technically prevented. A human user cannot add a new schema by himself.
¶ 5.1.2 Generic User (GU)
These kind of user accounts are not bound to any physical person and must only be used for applications, batch processes and the like if absolutely necessary or appropriate.
Generic users are subject to several constraints. While generic users are allowed to own a private sandbox, they are not allowed to become a sandbox master. Furthermore, generic users do not possess any impersonate rights.
¶ 5.1.3 Technical User (TU)
In 3-tier architectures the client authenticates against the application server, which then has to forward the identity of the physical person to the database. Further details can be seen in the following part of the guide (see section 5.2).
¶ 5.2 Logging onto the system
In 2-tier architectures the authentication happens directly through the database login using a personalized user account.
In 3-tier architectures however, the authentication takes places via an application. The identity of the physical person has to be forwarded to the database in this case. This works by impersonating a technical user (TU). The technical user takes on the identity of the human user (HU), which is logged on via the application, in the database itself. This impersonation function is provided by Exasol databases.
Newer 3-tier systems, like for example MicroStrategy, use personalized user accounts for directly authenticating against the database even if the login happened via a web application.
The next subchapters show the sequence of the authentication process. Additionally, a LDAP-server is included in the description. This is however optional. If no LDAP-server is used the user and password management is done directly by the database.
¶ 5.2.1 Authenticating using an LDAP directory
For the authentication against Exasol, an external LDAP-directory can be used. To be able to use a LDAP-directory, it has to be configured in Exasol beforehand. However, the configuration of such an integration of a LDAP directory into Exasol is not part of this guide.
¶ 5.2.1.1 Authentication in 2-tier environments
In 2-tier environments the authentication happens directly from the client application to the Exasol database. If a LDAP-directory is configured, the password will be queried from there.
The process covers the following steps:
- Client login: A person enters their username and password into the client application and the data is then send to the Exasol database
- Password enquiry: The database identifies the username and enquires from the LDAP-directory if the password is correct.
- Password confirmation: The LDAP-directory confirms the correctness of the password.
- Connection established: The database accepts the login and establishes the user-session to the client application.
The following graphic shows the beforementioned process of a login in a 2-tier system using LDAP.
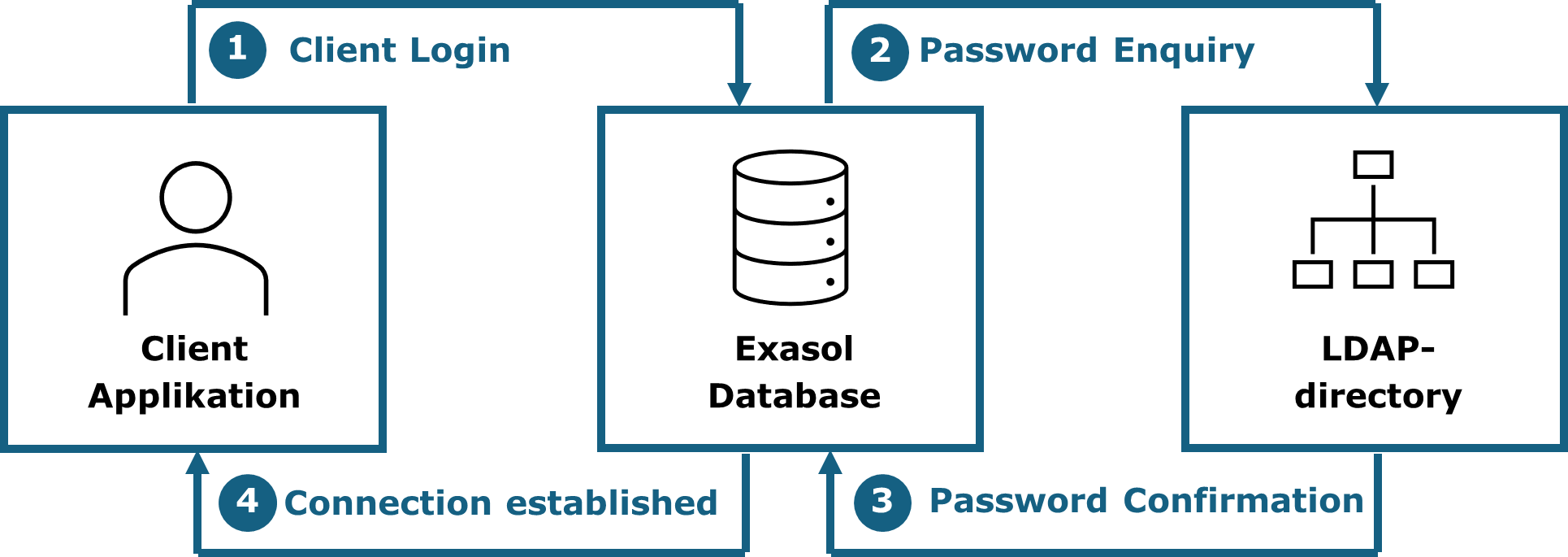
Figure 11: Authentication process in a 2-tier environment
¶ 5.2.1.2 Authentication in 3-tier environments
In 3-tier environments the web application authenticates against the application server, which then logs on to the Exasol database. If a LDAP directory is configured, the password is enquired from there. The process follows the steps below:
- Someone enters their username and password over the web interface. This data is then sent to the MicroStrategy server.
- The MicroStrategy server identifies the username and forwards the data for the login to the database.
- The database identifies the username and enquires from the LDAP directory if the password given is correct.
- The LDAP directory confirms the correctness of the password, leading to the user being logged on to the database.
- The database confirms the successful login to the MicroStrategy server
- The MicroStrategy server accepts the login, establishes a user-session and provides the client with the start page.
The following graphic showcases such a login on a 3-tier environment using a LDAP directory.
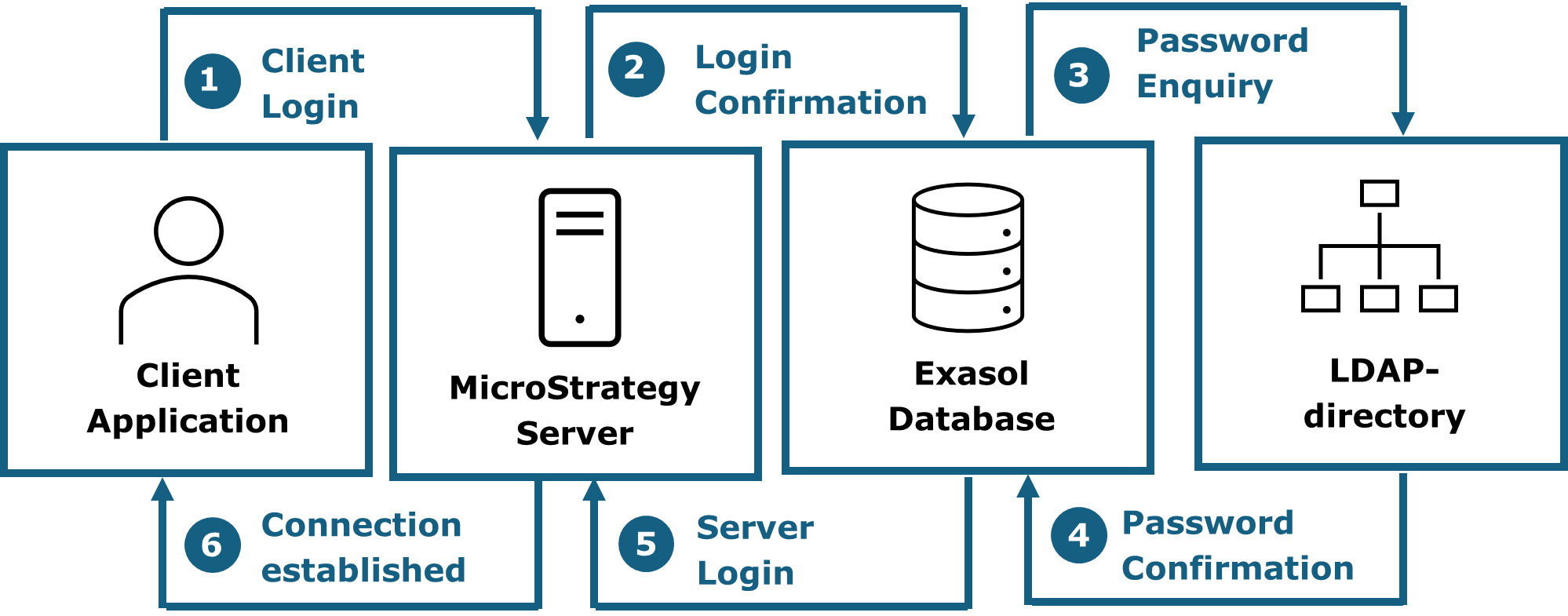
Figure 12: Authentication process in a 3-tier environment
¶ 5.3 Administration of user accounts
It is recommended to integrate an external identity management system, however, manual administration of users and rights via APIs is also possible.
Existing user accounts can be found under SCURTY -> Views -> REP_ALL_USERS.
¶ 5.3.1 Integration of an external identity management system
The creation of user accounts can be done automatically using an Identity Management System (IDM), if RED is configured to use such a system. The configuration of an IDM for RED is not part of this guide and should best be done in cooperation with Sphinx IT Consulting.
User accounts, sandboxes and rights can be managed automatically by integrating an Identity Management System (IDM) like Active Directory. The integration is done via views that map the respective IDM permission to the security concept (e.g. mapping of AD groups to object groups or tenants).
To add a new user to RED, the relevant access rights need to be set in the IDM, so they can be adopted by RED. User accounts automatically created using IDM, will also be managed by IDM further on. User accounts created that way can be identified in the table SCURTY.REP_ALL_USERS in the column “USER_COMMENT” by a leading “IDM:” in the string.
If a user account was created manually and the authorisation for the framework is then set in the IDM, this does not result in a conflict. The account is not recreated, but instead the permissions are reset to those defined in the IDM.
If RED is configured to use IDM, the current status and access rights of the IDM-provisioned user accounts, can be found in the SCURTY.IDM_% views.
ATTENTION: If an external Identity Management System (IDM) is being configured within RED, manually created user accounts with the same name as in the IDM will be updated regularly (usually daily) according to the access rights stored in the IDM.
User accounts that can been automatically created using IDM, will be locked, as soon as the access rights for RED have been revoked in the IDM.
¶ 5.3.2 Manual administration of user accounts via APIs
The framework offers several APIs to create, manage or drop users (API_SCURTY.CREATE_USER; .MANAGE_USER; .DROP_USER) and sandboxes and to grant or revoke privileges (API_SCURTY.GRANT USER_OG_ACCESS; .REVOKE_USER_OG_ACCESS). Furthermore, administration of object groups and tenants is solely done via API calls (API_SCURTY.ADD_OBJECT_GROUP; .CHANGE_OBJECT_GROUP; .REMOVE_OBJECT_GROUP).
To be able to execute the beforementioned script administrative privileges are necessary. These privileges can be granted to one or more security administrator accounts by the role R_SECMGR. The role allows to impersonate the user account SCURTY (“IMPERSONATE SCURTY;”). The original user account becomes the SCURTY user and therefore has complete access to all objects of this account.
¶ 5.4 Object Level Security
Object groups (OG) combine database objects into one group. This is done by using search rules in which a search pattern is defined using regular expressions. Such search patterns can be defined for schema names, object names as well as object comments. For each of these three types including and/or excluding patterns can be defined. The patterns are linked using “and”. This means each of the include patterns as well as none of the exclude patterns have to be met for an object to be added to an object group. Due to that, it is also possible to explicitly add or remove objects from an object group by changing the object comment accordingly. Several rules can exist per object group.
ATTENTION: If a search rule of an object group does not include any restrictions within a database schema, the whole schema will be added to the object group. This also includes any future existing objects of that schema. A search rule does not have any restrictions if the parameters “p_comment_incl_pattern” and “p_object_incl_pattern” are set to ‘.*’ while the parameters “p_comment_excl_pattern” and “p_object_excl_pattern” are set to NULL. If a ‘%incl%’ and a ‘%excl%’ parameter hold true at the same time for a schema, an object or a comment, the object is not added to the object group.
An hourly running internal process (REP_REFRESH) checks the search rules and adds or removes objects from object groups according to those defined rules. Objects cannot be manually removed from an object group. Objects can only be removed by editing the search rules accordingly. The timeframe within which the change is picked up by the processes is configurable. (SCURTY.ADM_JOBS paragraph “general control tables and views”)
Object groups are implemented as roles in the database and are mainly used for views in the PSV (reporting) layer.
User accounts can be granted access to one or more object groups. Access rights can either be manually granted via LUA scripts by a security manager or automatically using the IDM system. The current access rights are stored in the table SCURTY.REP_USER_OG_ACCESS.
ATTENTION: To be able to grant access rights towards object groups, they have to be created first, as access rights can only be allocated to already existing object groups. Existing object groups can be found in the table SCURTY.REP_OBJECT_GROUPS. Furthermore, WRITE access can only be granted to object groups, which have been created with WRITE access and access rights can only be granted to classified user accounts, meaning users from type “HU” and “GU”.
Information from the Identity Management is regularly transferred into the RED framework and saved in the table SECADM.IDM_BASE. A daily running process called “IDM_REFRESH” creates access rights depending on that information. These access rights are being saved to SCURTY.REP_USER_OG_ACCESS same as if granted manually.
The timeframe for when the “IDM_REFRESH” process should run is configurable and saved to the table SECADM.ADM_PARAMS (PAR_NAME = idm_refresh)
ATTENTION: If IDM is configured and access rights of a user account, which is managed by IDM, are modified manually, these modifications will be reversed with the next IDM refresh run.
ATTENTION: The fact that a user has access to an object group does not necessarily mean that he or she has access to data. Row or column level security might prevent the user from even seeing a single row.
¶ 5.5 Row Level Security
Access to data in the PSV views can be restricted at row level depending on the user account. For example, access can be limited to a particular business domain or every other suitable attribute. For this purpose, table fields are identified which can be used to decide whether access to a row is granted. Such a field then belongs to a security tenant. Examples of tenant columns are "BDOMAIN", "BRANCH" or "REGION".
A user account is granted access to one or more tenants, depending on the object group. A tenant works like an implicit SQL Where condition that is fixed and cannot be changed. Access to certain tenants is again done either manually by a security manager or automatically by an IDM system.
¶ 5.6 Column Level Security
In addition, access to data in the PSV views can be restricted at column level depending on the user account. For example, access can be limited for specific sensitive columns (e.g. marginal return, …). Those columns must be defined in a similar way to tenants in the chapter above. The select list of a table with sensitive columns will be modified and cannot be changed. Depending on the access, a user will either be able to see the column value or just null. Access to sensitive columns is again done either manually by a security manager or automatically by an IDM system.
¶ 5.7 Sandboxing
Sandboxes are database schemas in which objects can be created that are used, for example, for development, tests, evaluations or analyses. Sandboxes are "playgrounds" and should not be used for productive use, e.g. for reporting or ETL processes.
There are two types of sandboxes:
- Private sandboxes
- Project-related sandboxes
¶ 5.7.1 Private Sandboxes
A private sandbox is a schema that is assigned to exactly one user account and is provided with quotas. Objects created in this schema must not be used by other user accounts. The transfer of rights (grants) is prohibited and is also technically prevented. Within a private sandbox, there are no access restrictions at object or row level. The user account owns the objects in the private sandbox and therefore has full access to them. A private sandbox cannot be given an expiry date. Quotas (storage space) on private sandboxes are assigned manually or automatically. Only one private sandbox can be created per user account.
¶ 5.7.2 Project-Related Sandboxes
If a schema is to be used jointly by several people, a project-related sandbox must be created. A project-related sandbox is a database schema to which several user accounts ("sandbox masters") can be granted permissions. In project-related sandboxes, the same permissions apply with regard to data access as outside the sandboxes. Depending on the user accounts, restrictions therefore apply at object, row and column level.
In addition, the "least privilege principle" applies in sandboxes, i.e. only the data to which all user accounts have permissions is visible. A user account with fewer permissions therefore also restricts access rights in the sandbox for users with extended permissions. The intersection of permissions always applies.
Each project-related sandbox receives a limit for the maximum storage space (quota), which can also be infinitely large. Quotas for project-related sandboxes are assigned manually or automatically. A project-related sandbox can optionally be provided with an expiry date. After a project-related sandbox expires, it is locked and can no longer be used. If the expiry date is changed to a date in the future, the sandbox is unlocked again and can be used again, continuing as if the sandbox was never locked.
The person who requests a project-related sandbox is called the "requestor". He or she can receive notifications with updates about the sandbox (e.g. creation, locking, unlocking, …) to an email address, if provided.
¶ 5.8 Auditing
Complete SQL auditing can be done by the Exasol database. When activating this feature, every interaction with the database is monitored and can be used to investigate possible incidents. A detailed description can be found following this link:
Exasol Auditing
¶ 6 GDPR Module
This module enables the data storage to meet the GDPR compliance requirements by anonymising historical data in the data warehouse. It consists of multiple components working together to anonymize data. It is designed to anonymize individual data that has been deleted or obscured in source systems. To function correctly, it requires a domain expert familiar with the tables, their meanings and purposes. All configurations are historically recorded to pass potential audit inspections.
¶ 6.1 Process
The framework's first component is an own GDPR schema, which contains the metadata repository for configuring and controlling the anonymization. It includes information about the tables and columns to be anonymized, as well as the anonymization rules to be used.
Anonymization is carried out using rules, as they determine which values in selected columns should be replaced. It is crucial that the new value fits into the target data type column. If the data type changes over time, this is registered and stopped before a run (unless the target value is NULL).
Furthermore, the configuration also includes dedicated columns representing the business key, whose values are delivered through normal historization.
The configuration could, for example, include tables such as "Customers," "Accounts," and "Transactions," with anonymization rules possibly replacing customer IDs, bank account numbers, and other sensitive data with specific values.
The framework overwrites anonymized fields, and the original can only be restored through a data backup. Anonymization can also cause existing logical constraints to show inconsistencies.
Some benefits of the anonymizer for historical data in a DWH are:
- Every configuration is auditable.
- Flexible and configurable for any source.
- Configuration checks before each run.
- Column values are overwritten or deleted.