¶ BlueBoxx-X3
Revolutionize the stability and performance of your enterprise IT: With BlueBoxx-X3, you can rely on the ultimate platform for all your IT applications. Leveraging innovative container-based deployment of OpenStack, we achieve what was previously considered unattainable: Unrestricted availability and zero downtime for your Infrastructure-as-a-Service (IaaS) – thanks to seamless rolling upgrades. Experience the future of company IT, today with BlueBoxx-X3.
¶ What does BlueBoxx-X3 offer?
BlueBoxx-X3 offers several benefits for a company.
-
High Availability: This is achieved through complete redundancy. BlueBoxx is designed to be fully redundant down to its last component, ensuring no single point of failure. If a split across different disaster zones is wanted, business continuity can be even ensured in the event of an elementary disaster. The positioning of nodes can be done either at the company's premises or in a data center, as per choice.
-
Infrastructure as a Service: The Openstack cluster data is aggregated into a central database, which enables additional features such as data balancing between multiple storage nodes. If a node exceeds a certain load threshold, data or VMs can be moved according to predefined allocation criteria to other nodes. It is also possible that instances in the cloud are started and data or VMs are outsourced to them according to predetermined allocation criteria once a certain load limit is reached.
The integration of orchestration services such as Heat makes it possible to deploy infrastructure-as-a-service (IaaS) environments and automate resource management. Additionally, required virtual machines can be provisioned via API in minutes. Furthermore, the management through Dashboard simplifies handling. In the Dashboard, for example, new VX:LANs can be created or new VMs spawned. To spawn a new VM, only the desired image, RAM, storage size, storage medium, and authentication type need to be selected. This simple graphical user interface makes creating VMs easy, as only forms need to be filled out, while the actual implementation takes place in the background based on the input provided.
-
High-Performance: In a world where speed has become a crucial competitive factor, BlueBoxx provides the necessary performance to stay ahead of the game. Our innovative design, built on top of the proven OpenStack components, achieves unparalleled high-performance by optimally connecting compute and storage nodes. This BlueBoxx architecture allows even the most demanding workloads, such as executing computationally intensive applications, scaling resources according to demand, or ensuring lightning-fast data access, to be easily managed.
Furthermore, BlueBoxx enables latency times reduced to a minimum and maximum throughput rates thanks to direct communication between compute and storage nodes. This means that our customers can enjoy faster application response times, resulting in happier users and a more agile and competitive business.
-
Near Zero Data Loss Backups: This is ensured through atomic snapshots of the entire environment and immutable data protection. Traditional backups are thus only necessary in exceptional cases anymore. Also regular restore tests and daily operational handling are no longer required due to BlueBoxx. Snapshot mechanisms below the virtualization layer, which allow for near-realtime distribution to any number of remote sites, are one of the reasons for the elimination of these extra efforts.
Without additional costs or effort, this results in a recovery point objective which is only in the minute range while the recovery time objective is even in the range of seconds. Moreover, snapshots themselves are immutable and secure against changes and man-in-the-middle attacks. Additional encryption also allows storing them in public cloud environments.
-
No Vendor Lock-in: For BlueBoxx, only open-source solutions are used, which prevents vendor lock-in. This means that customers are not tied to specific providers or proprietary technologies, which often leads to long-term cost pitfalls and limited flexibility. With OpenStack as its foundation, BlueBoxx customers benefit from the dynamic development of a global community that is open to innovation and adaptation to new technological trends.
This enables seamless integration of new services and features without the limitations of proprietary ecosystems. Furthermore, our customers can adapt their IT infrastructure to their needs without having to worry about compatibility with a specific provider by forgoing proprietary solutions. Whether it's storage, networking, or security solutions - the choice remains free as long as they conform to open standards.
-
Integration Partnership The modern digital landscape is characterized by diversity and interoperability. In addition, we strive for a sustainable approach to resources within the company, utilizing existing hardware whenever possible. Therefore, at BlueBoxx, we understand the importance of seamless integration with existing systems and tools.
As a reliable partner, we offer customized integration partnerships that aim to perfectly integrate BlueBoxx into our customers' individual IT infrastructures. Thanks to our "Moving Migration" offering, it's even possible to migrate to the already existing hardware during ongoing operations with minimal downtime.
-
Automated Scaling: Through the use of MaaS, added physical resources are automatically recognized and the IaaS (Infrastructure as a Service) is expanded. When connecting a resource via its Remote Management Interface (IPMI, DRAC, iLO, etc.), the necessary information is read out and the resource is provisioned.
By analyzing threshold values and resource data, it can be automatically determined whether the resource should be added as a compute or storage node. Based on this decision, the automated provisioning function of the node is triggered with the relevant containers.
-
Ransomware-Proof: Because an unalterable and atomic snapshot is made every 5 minutes, a rollback to a point before the ransomware attack can be performed within seconds. Even taking the best security measures, a hacker attack, resulting in the encryption of the data across the entire system, can not always be prevented. According to studies this can lead to a standstill of the entire company for several days. With BlueBoxx though, a complete and consistent restoration of the entire application world can be guaranteed within a few minutes or even seconds.
-
Flexible and Scalable Network Architecture: OpenStack Neutron provides a flexible and scalable network architecture that enables the creation of virtual networks (VLANs), VLAN encryption, and firewall rule definitions. By using Neutron, administrators can improve their network efficiency by focusing on providing network resources.
Furthermore, Neutron allows for integration with various Network Functions Virtualization (NFV) technologies, such as Software-Defined Networking (SDN). This integration enables companies to improve their network efficiency, security, and scalability.
-
Tested Releases: The continuous improvement and expansion of BlueBoxx is our top priority. Therefore, our team conducts thorough testing at every new release, before it goes live, to ensure that BlueBoxx meets the highest quality and security standards.
Such releases can be for updates as well as new features. This includes both automated tests and manual examinations by our experts to eliminate any potential vulnerabilities. The result are releases that not only offer innovative functions but also reliability and safety.
With BlueBoxx, our customers benefit from an optimal balance between innovation and stability. This means that they can take advantage of the latest advancements without compromising on the security and dependability of their systems.
-
Guaranteed Functionality: At Sphinx, we fully stand behind the quality and performance of our BlueBoxx solution. That's why we offer our customers a comprehensive functionality guarantee.
If ever problems should arise with the functionality of BlueBoxx that couldn't be prevented by our proactive maintenance, we work closely with our customers to identify the cause and develop a solution that minimizes disruption to their operations.
-
Full Management: BlueBoxx is managed by the Sphinx team as a Managed Service. This means that our experienced team continuously monitors all components of BlueBoxx to ensure that every aspect of the solution - from infrastructure to applications - operates smoothly.
Through proactive maintenance and immediate response to potential issues, we minimize downtime and guarantee maximum uptime for critical workloads. With BlueBoxx, our customers can focus entirely on their core business, while we handle the behind-the-scenes tasks to ensure everything runs as expected.
-
7 x 24 proactive Monitoring: A proactive approach is key to preventing problems from arising in the first place. That's why we place great emphasis on comprehensive monitoring of all system aspects for our BlueBoxx solution.
Our powerful monitoring system provides real-time insights into the performance, security, and integrity of the platform, enabling early warnings for potential issues, and allowing our team to take corrective action often before our customers even become aware of a problem.
-
Third-Level Support: A top-notch support team is the foundation of any successful solution. We offer a Third-Level Support for BlueBoxx that goes beyond common service standards. While First- and Second-Level Supports often only cover general inquiries and basic technical issues, our Third-Level Support is specifically designed for complex, in-depth technical challenges.
Our experts on this level work directly with developers and system architects to develop individual solutions for particularly demanding problems. With this top-tier support, we ensure that even the most complex challenges become no barrier to success for our customers.
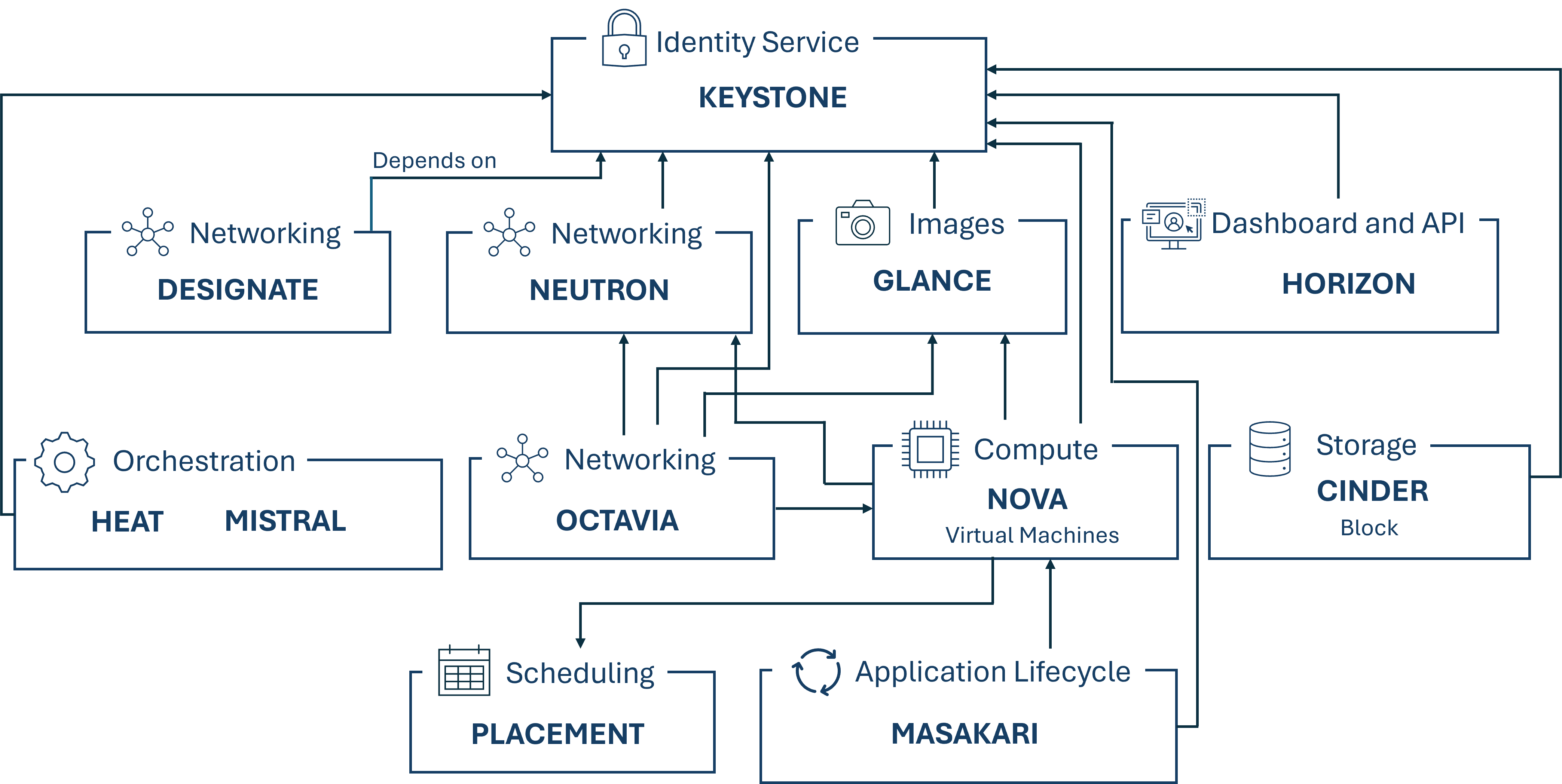
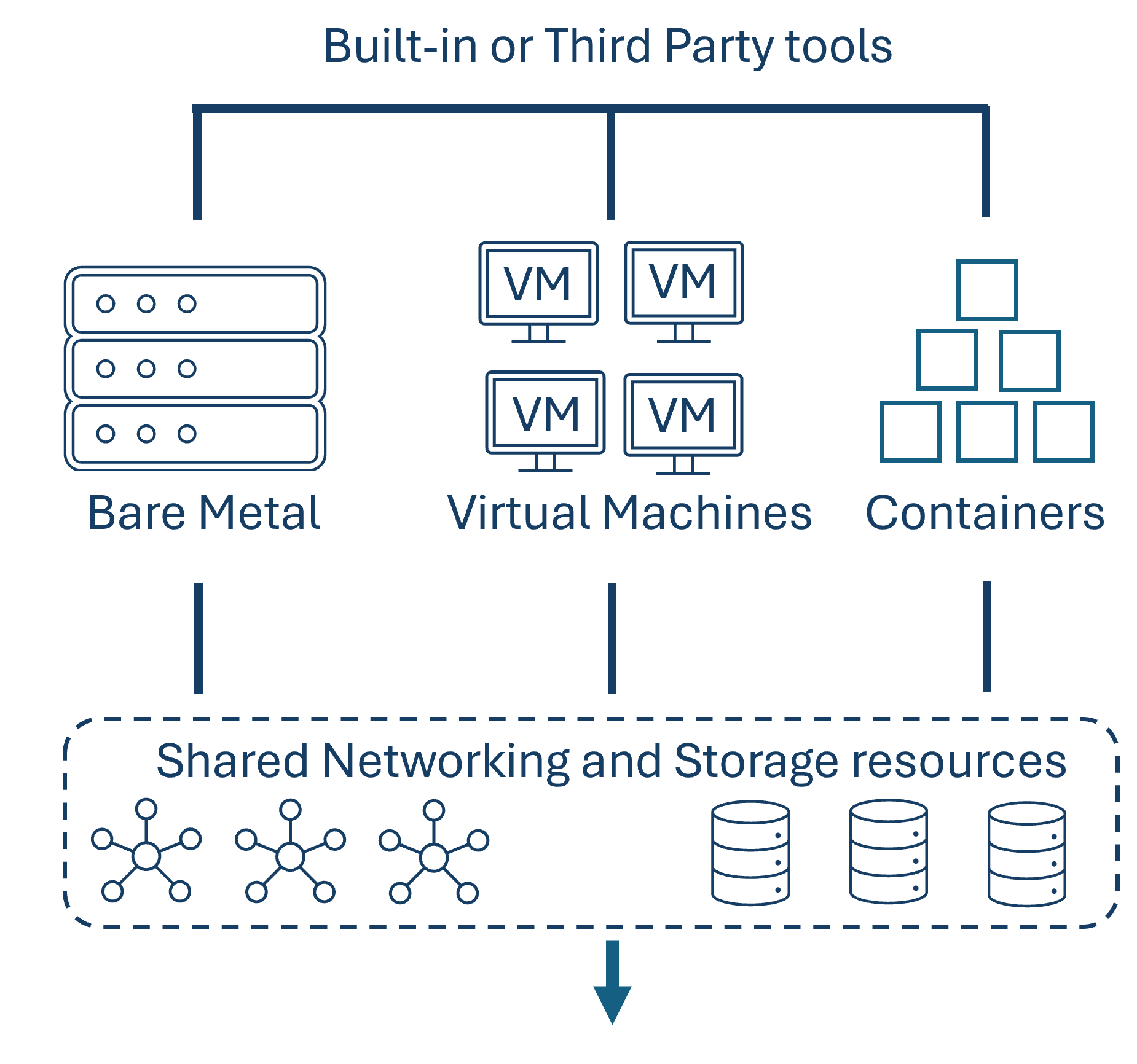
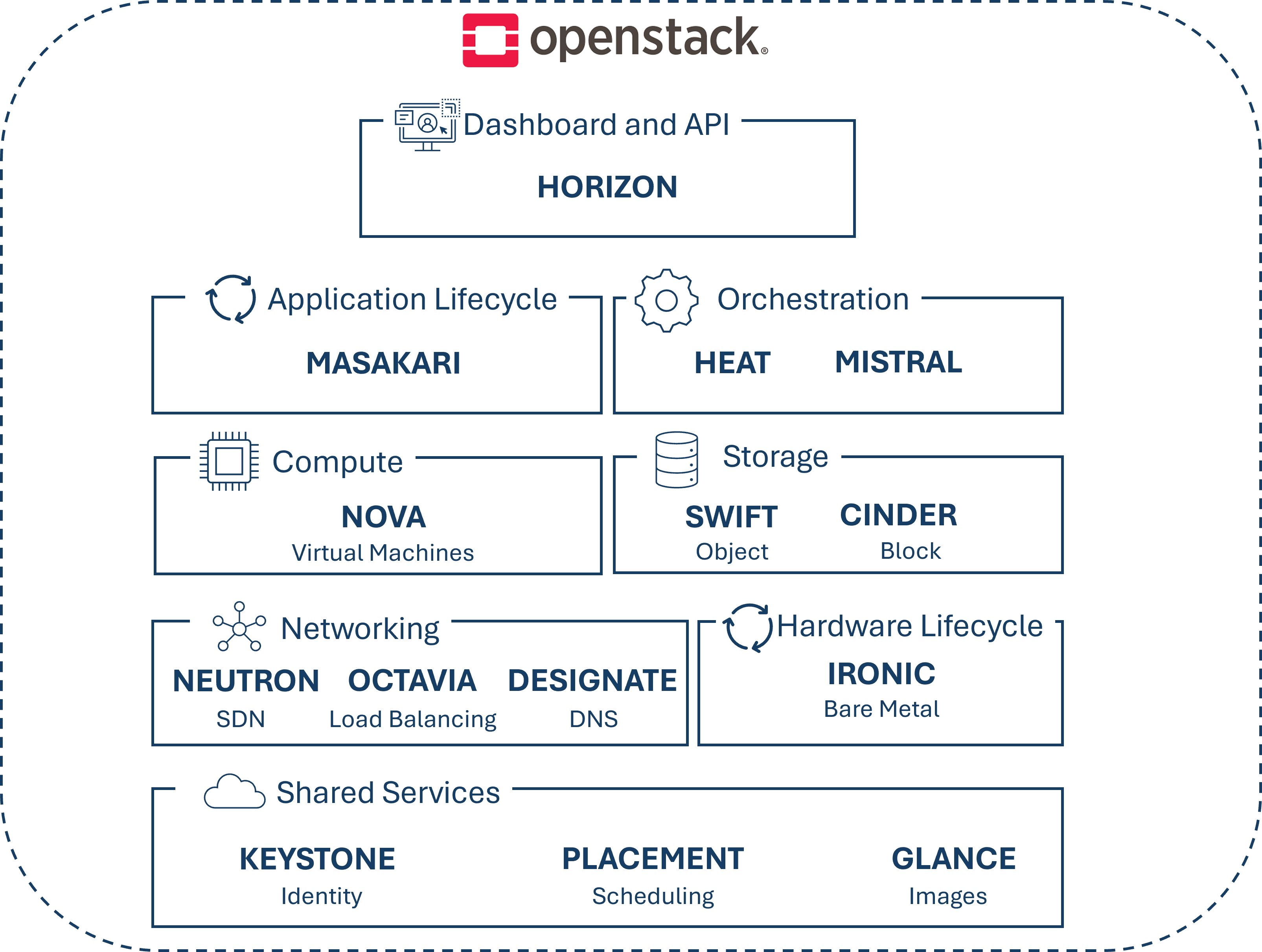
¶ BlueBoxx-X3 Infrastructure
The following figure shows the infrastructure as well as the OpenStack components that we use in our BlueBoxx-X3 solution.
¶ Used Components
Following the components of the OpenStack service stack we used.
-
Horizon:
This is the OpenStack dashboard, which provides a web-based user interface to the OpenStack services such as Nova, Swift, or Keystone. Additionally, settings for nodes can be made here, such as setting up the size of a new storage space or specifying the driver to use.
Horizon was designed as a registration pattern for applications so that they can easily connect to it. Today, Horizon comes with three central dashboards: "User Dashboard", "System Dashboard", and "Settings Dashboard". These three dashboards cover all core OpenStack applications and provide core support.
The Horizon dashboard application is based on the dashboard class, which provides a consistent API as well as a set of features for both built-in core OpenStack dashboard applications and third-party applications. This dashboard class is treated as a top-level navigation item. When a developer wants to add a specific functionality to an existing dashboard, it's as simple as creating a new dashboard thanks to the easy registration pattern that allows writing a new application that connects to other dashboards. All they have to do is import the dashboard that should be changed.
To prevent files from growing thousands of lines long and make code easier to find by correlating it directly with navigation, OpenStack provides a simple method for registering panels. These represent the entire necessary logic of an interface and are considered sub-navigation items.
Horizon relies on the "Keystone" component.
-
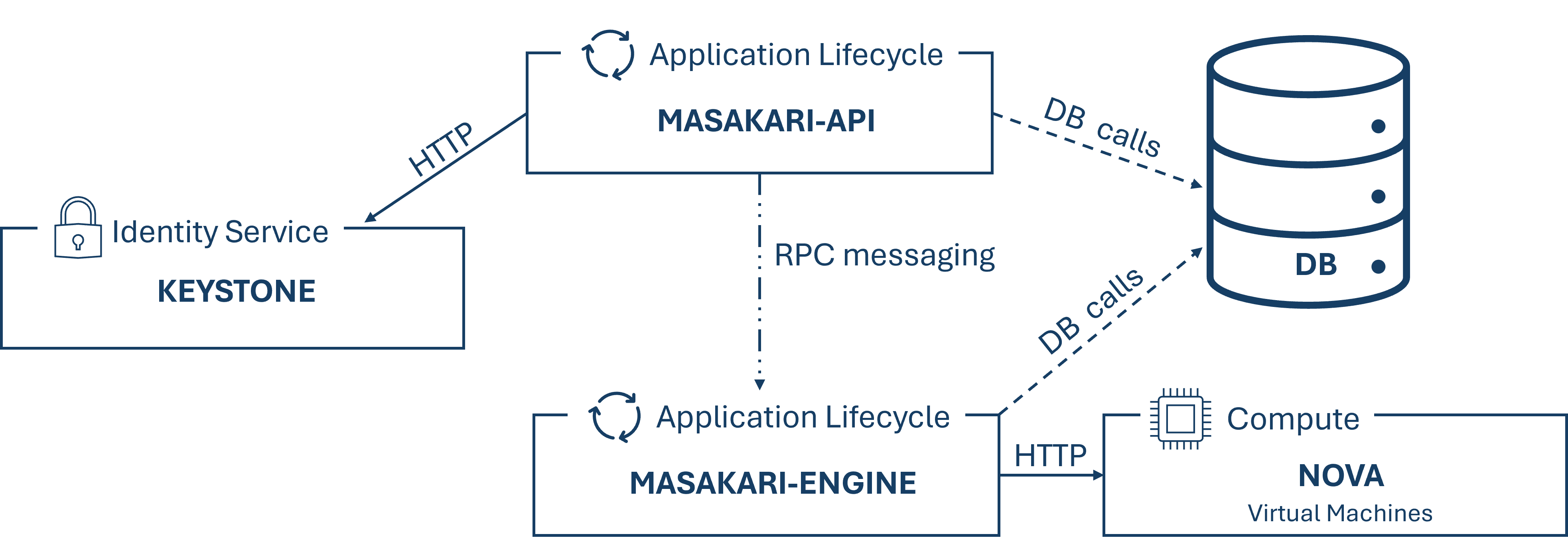
Masakari:
Masakari offers an instance high availability service for OpenStack clouds by automatically restarting failed instances or compute processes. To manage and control this automated recovery mechanism, Masakari also provides an API service. It can automatically restart KVM-based virtual machines from failures such as virtual machine process down, provisioning process down, or nova-compute host failure.
Masakari consists of two services: an API and an engine, which perform different functions. The API server processes REST requests, typically involving database read/write calls, converts the commands, sends RPC messages to the engine, and generates responses to the REST requests. The engine runs on the same host as the API and has a manager that reacts to RPC messages and performs periodic tasks. Additionally, the engine executes the recovery workflow and communicates with Nova via HTTP.
Masakari relies on the OpenStack components "Keystone" and "Nova". The communication architecture of these key components is depicted in the following figure.
-
Heat:
Heat is an OpenStack component for orchestrating infrastructure resources for cloud applications. This orchestration is achieved through templates in the form of text files, which can be treated like code. Such a template describes the infrastructure of a cloud application in a human-readable and writable format, allowing for management using version control tools. Since these templates describe the relationships between resources, this enables Heat to inform the OpenStack APIs of the correct order to create the planned infrastructure, so that the subsequent application can be started.
With these templates, most types of OpenStack resources, such as instances, floating IPs, volumes, security groups, and users, can be created. Additionally, they also offer more advanced features like instance high availability, autoscaling of instances, and nested stacks. This autoscaling service allows for the integration of OpenStack Telemetry, thereby enabling the integration of scaling groups as a resource in a template.
While Heat is primarily designed to manage infrastructure, the templates can be easily integrated with software configuration management tools like Ansible and Puppet. Heat provides both an OpenStack native REST API and a CloudFormation-compatible query API.
Heat relies on the component "Keystone" for authentication and authorization.
-
Mistral:
Mistral is a workflow service. Most business processes consist of multiple steps that are dependent on each other and must be executed in a specific order within a distributed system. Such a process can be described as a set of tasks and their relationships, typically using a YAML-based language. A description like this can be uploaded to Mistral so it can handle state management, correct execution order, parallelism, synchronization, and high availability.
Tasks that are executed through Mistral can be anything from running local processes like shell scripts and binaries on a specific virtual instance to calling REST APIs that are accessible in a cloud environment, down to cloud management tasks like creating or deleting virtual instances. Even nested workflows can be executed using Mistral by having it jump back into the parent workflow and continue with the provided variables after executing the new workflow.
Mistral is particularly important when multiple tasks need to be combined into a single workflow that must be executed in a specific order or at a certain time. In such cases, Mistral ensures parallel execution of independent tasks, fault tolerance in case one node crashes during a multi-step workflow, and workflow execution management and monitoring capabilities.
Mistral itself does not execute tasks but coordinates other worker processes that perform the actual work and then report back to Mistral with their results. While Mistral already provides users with a set of standard actions for tasks, it also allows users to create custom actions based on the standard package. To visualize workflows used in Mistral, the workflow visualization tool "CloudFlow" can be used. Such visualizations can also help identify errors or weaknesses in a workflow.
Mistral relies on the "Keystone" component.
-
Nova:
Nova is a service used for provisioning compute instances. It supports creating virtual machines and in collaboration with Ironic also creating bare metal servers. It also has limited support for system containers and provides these resources through a self-service platform. Nova is modularly designed to ensure scalability, flexibility, and maintainability. The support Nova offers for various hypervisors, therefore covering a wide range of virtualization technologies contributes to this flexibility.
One of the supported hypervisors is VMwareESX, which belongs to the VMware product family, enabling access to advanced features such as vMotion, high availability, and dynamic resource allocation (DRS) for virtual machines. Nova can communicate with the vCenter server, the VMware ESX API, which manages one or more ESX host clusters. These clusters are presented to Nova as a single large hypervisor entity. The actual selection of an ESX host within these clusters is performed by vCenter using DRS. It is recommended to run one Nova Compute service per ESX cluster. Furthermore, the hypervisors are interchangeable as long as a corresponding driver is available, thanks to communication through an API.
Nova consists of the API, Scheduler, Compute, and Conductor modules. While the API module receives and processes API requests from users and other OpenStack services, also handling authentication through integration with Keystone for access management and security, the Scheduler module decides on the optimal distribution of workload across available resources based on available resources and filter criteria, by deciding on which compute node a new virtual instance should be started on. The Compute module manages virtual machines on compute nodes by starting, stopping, modifying, or deleting them. It also provides hypervisor support for various hypervisors like Hyper-V, VMware, Xen, or KVM. The last module, the Conductor module offers a trusted environment for sensitive operations that should not be performed directly on the compute nodes for security reasons. It can also take over tasks from other Nova components to reduce their load.
The interaction between these modules when creating an instance is explained in the following figure:
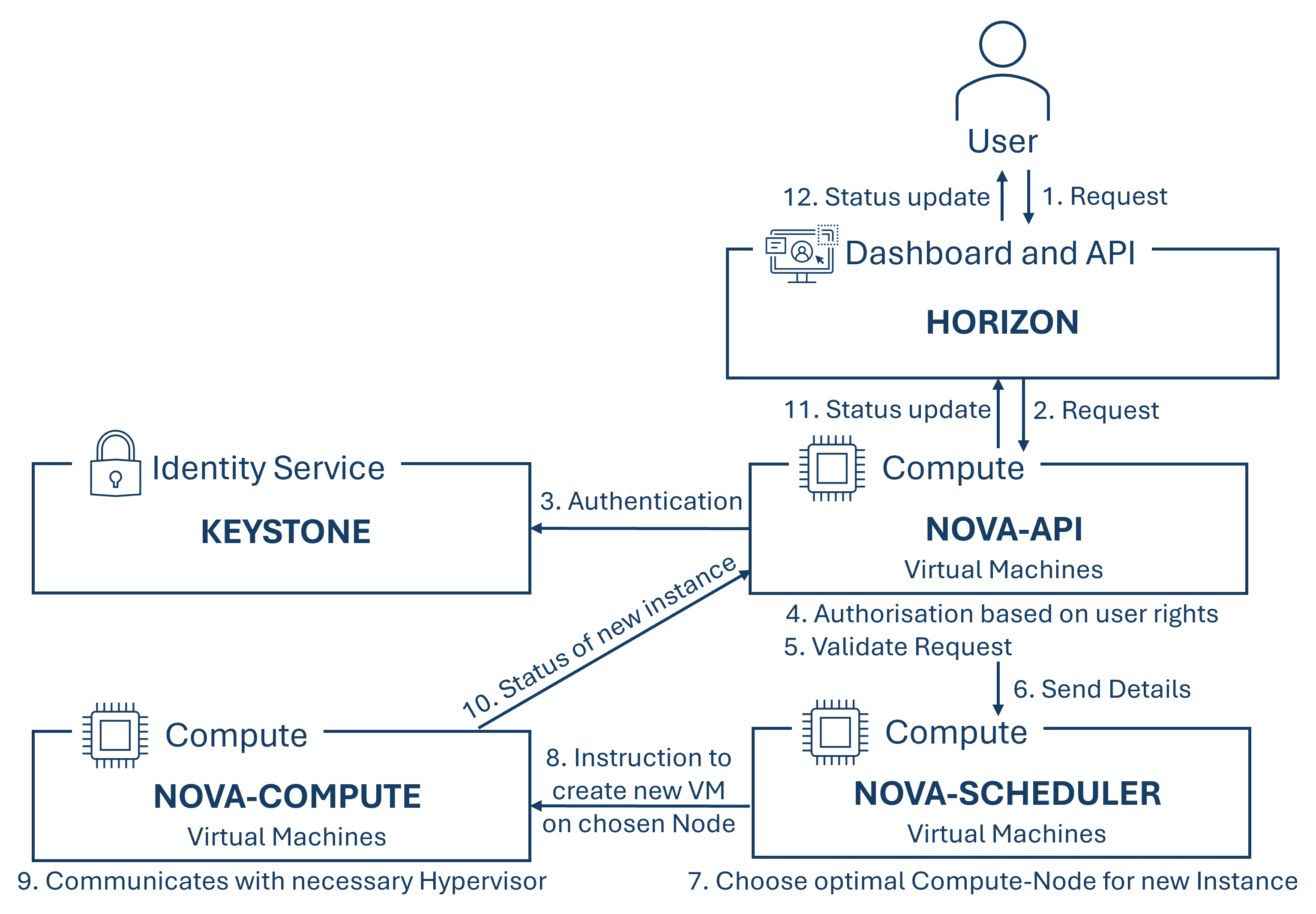
Nova depends on the components "Keystone", "Neutron", "Glance" and "Placement".
-
Swift:
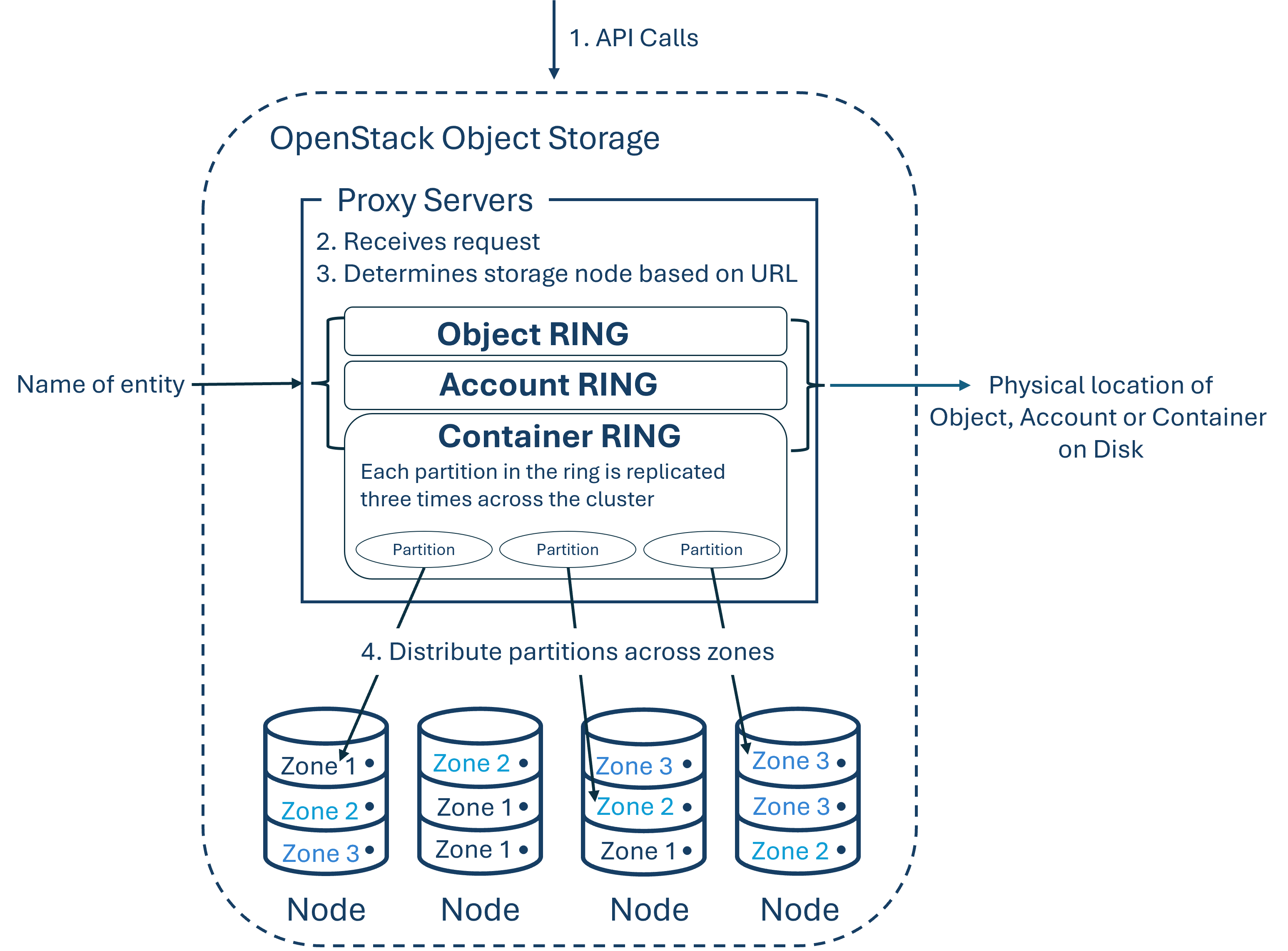
Swift is a distributed, highly available, and eventually consistent object or blob store that enables companies to store data efficiently, securely, and cost-effectively. It is designed for scalability and optimized for durability, availability, and concurrency across the entire dataset. Swift is ideal for storing unstructured data that can grow indefinitely in size. This is possible because object stores use a distributed architecture where there is no central control, but rather objects are stored on multiple hardware devices, and Swift takes care of replicating and maintaining the integrity of the data distributed across the cluster.
The storage clusters are horizontally scalable by adding new nodes as needed. If one node fails, Swift ensures that the data is replicated to other active nodes. By taking care of replication and distribution, Swift allows for using cost-effective, standard hard drives and servers for the storage cluster, thereby also preventing vendor lock-in. Additional benefits of object stores include their self-healing capabilities, unlimited storage space, easy scalability, high availability, better performance due to the absence of a bottleneck as no central database exists, the ability to set an expiry date for objects as well as the possibility to restrict access to containers per account, direct access to objects, and no need for RAID configurations.
Characteristics of object stores include:
- Each object has a unique URL.
- Different "storage policies" can be created to specify different levels of durability for objects in the cluster.
- All objects have their own metadata.
- Object data can be located at any point in the cluster.
- New nodes can be added to the cluster without downtime.
- Faulty nodes or disks can be replaced without downtime.
- Standard hardware can be used for the cluster.
An object store consists of multiple components to provide high availability, durability, and concurrency. Proxy servers handle incoming API requests, rings map the logical names of data and their storage location on a specific disk, zones isolate data from different zones from each other, ensuring that an error in one zone does not affect the rest of the cluster, due to the data being distributly replicated over several zones and objects are the actual data itself. Weiters gibt es Accounts und Containers. Additionally, there are accounts and containers. Each is a separate database distributed across the cluster. While the account databases contain a list of all containers belonging to the account, a container database keeps track of all objects within this container. Partitions store objects, account databases, and container databases and help manage the storage spaces where these data are stored at the cluster.
These components and their interactions are illustrated in the following figure:
-
Cinder:
Cinder is a block storage service, that virtualizes the management of block storage devices. This allows end-users to request and use these resources through an API without having to know where they are located or what type of device they are stored on. Cinder provides block-based storage resources as volumes for Nova virtual machines, Ironic bare metal hosts, and containers. The benefit of using such volumes is that they can exist independently of the lifespan of a virtual machine. This means that even after a virtual machine is deleted, the data remains.
Additionally, attaching and detaching volumes from virtual machines is a simple process, allowing for flexible resource allocation. Cinder supports a variety of storage backends, including local hard drives and external storage systems like NAS, SAN, or Ceph, which enables efficient utilization of existing storage capacity.
Cinder also provides features for creating snapshots and backups. Thanks to its component-based architecture new behavior patterns can be added quickly, and Cinder also offers a high availability, due to its scalability. It is also fault-tolerant because cascading failures are prevented through isolated processes. If errors do occur, Cinder can be restored by simply diagnosing, debugging, and fixing the issue.
The Horizon user interface can be used to create and manage volumes via Cinder.
Cinder depends on the component "Keystone" for authentication and authorization purposes. This means that Keystone provides the necessary credentials and permissions for Cinder to access storage resources and manage them accordingly.
-
Neutron:
Neutron is a software-defined networking (SDN) project that provides Networking-as-a-Service (NaaS) in virtualized environments. It enables the creation and management of networks, as well as the configuration of network functions for virtual machines within the cloud.
Due to its open architecture, Neutron can be integrated with various networking technologies and devices. Additionally, it offers features such as VX:LANs (Virtual Extensible LANs) and Firewall-as-a-Service (FWaaS). With VX:LANs, the number of possible virtual LANs is not limited like it is with VLANs. Neutron routes virtual networks to physical networks using Network Address Translation (NAT).
To configure a new virtual network using Neutron, an administrator only has to create a new virtual network, including all subnets, routes, and security groups via Horizon. These configuration requests are then processed by Neutron, which configures the physical network infrastructure by communicating with corresponding plugins and agents. Once configured, these networks can be easily assigned to a virtual machine when it is created by selecting the appropriate one.
Neutron relies on the "Keystone" component for authentication and authorization purposes. This means that Keystone provides the necessary credentials and permissions for Neutron to access and configure network resources.
-
Octavia:
Octavia is the load-balancing component of OpenStack. By scaling its fleet of virtual machines, containers, and bare metal servers, also known as amphorae, on demand to handle load distribution tasks, this horizontal scaling function differentiates Octavia from other load balancing solutions and makes it truly suitable for cloud environments.
Octavia is responsible for distributing incoming network traffic across multiple servers to ensure high availability and optimal resource utilization. Multiple drivers are supported, and Octavia can be integrated with Neutron.
To be able perform its tasks, Octavia uses several OpenStack components:- Nova: To manage the amphora lifecycle and provision compute resources on demand
- Neutron: For networking connections between the amphora, tenant environments, and external networks
- Keystone: For authentication against the Octavia API and other OpenStack projects
- Glance: To store virtual machine images
- Oslo: For communication between individual Octavia controller components
Furthermore, the Octavia controller, which is the brain of Octavia, consists of 5 components that are individual daemons running on different back-ends. The API Controller receives API requests, performs simple sanitizing on them, and forwards them to the Controller Worker via Oslo messaging. This worker component takes the sanitized data and executes all actions necessary to fulfill the request. The Health Manager monitors individual amphorae to ensure that all amphora are running and healthy, and handles failover in case one unexpectedly fails. The Housekeeping Manager cleans up deleted databases. Finally, the Driver Agent receives status and statistics updates from the provider driver.
The following figure illustrates the communication between the different Octavia components as well as with other OpenStack components.
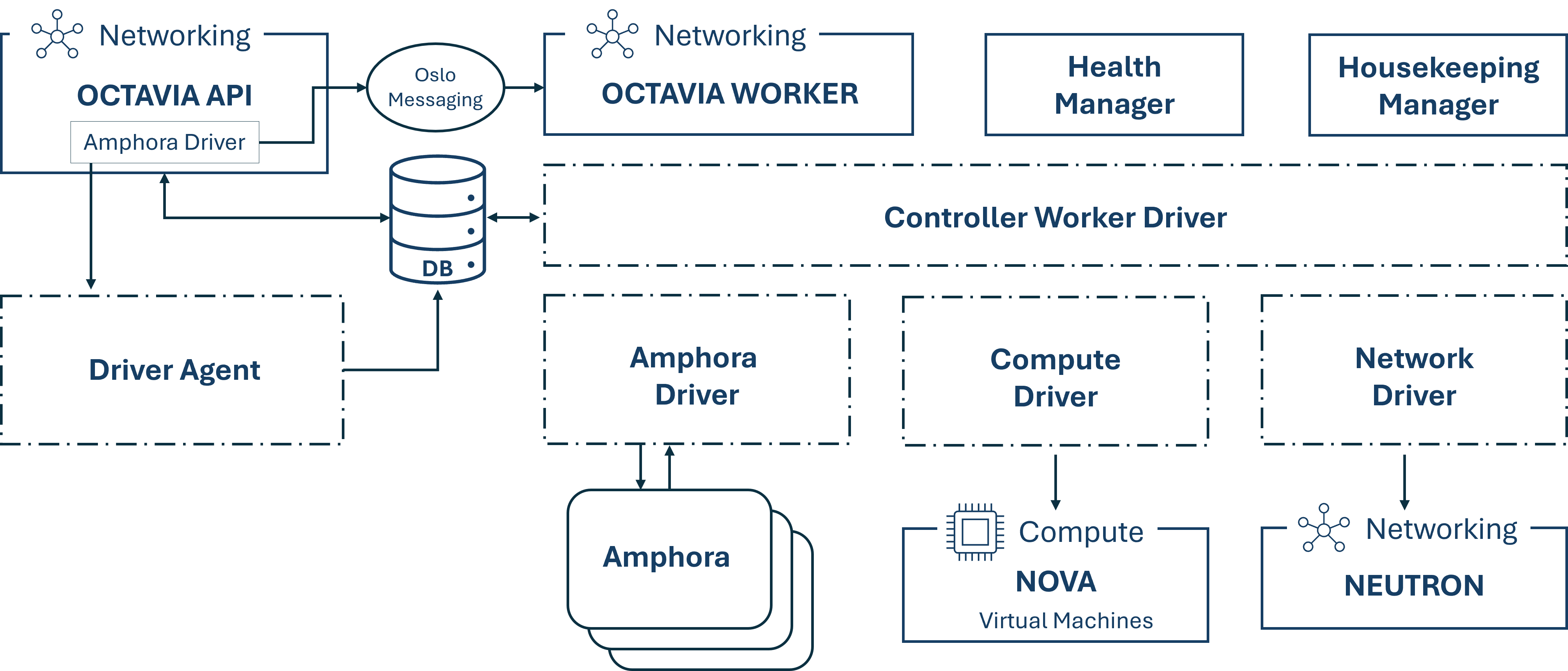
Octavia depends on the components "Keystone", "Glance", "Neutron" and "Nova".
-
Designate:
This component provides DNS-as-a-Service, offering a REST API with integrated Keystone authentication and configuration options for automatic record generation based on Nova and Neutron actions. Furthermore, it supports various DNS servers, such as Bind9 and PowerDNS 4.
Designate consists of five services, the API, Producer, Central, Worker, and Mini-DNS. Multiple copies of each service can run simultaneously to ensure high availability. Designate uses an oslo.db-compatible database to store data and status, as well as an oslo.messaging-compatible messaging queue for communication between services.
When networks are created in Neutron which are added to a previously created Designate zone, the addition of a virtual machine to one of these networks triggers the automatic creation of an entry at the Designate nameserver. This update of zone information is initiated by the Worker and then queried from the Mini-DNS for updates. Both forward and reverse entries are subsequently added to the nameserver.
Designate depends on the Keystone component for authentication and authorization.
-
Ironic:
Ironic is the component responsible for provisioning bare-metal machines. Integrations with Keystone, Nova, Neutron, Glance, and Swift are possible. Ironic allows managing hardware using standard protocols such as PXE and IPMI, as well as vendor-specific remote management protocols. It also provides for users a unified interface to the heterogeneous mass of servers, as well as an interface for the compute component Nova, allowing Nova to manage physical servers like virtual machines.
Bare-metal servers are provisioned in the cloud for various purposes, some of the most important being high-performance computing clusters and tasks that require access to hardware devices that cannot be virtualized. Key technologies for bare-metal hosting include PXE, DHCP, NBP, TFTP, and IPMI.
Preboot Execution Environment (PXE) allows a system's BIOS and network interface card (NIC) to bootstrap a computer from the network instead of from disk. Bootstrapping is the process during which the system loads an operating system into local memory so that it can be executed by the processor. Dynamic Host Configuration Protocol (DHCP) dynamically distributes network configuration parameters, such as IP addresses for interfaces and services. When using PXE, the BIOS uses DHCP to obtain an IP address for the network interface so that it can find the server where the network boot program is stored. The Network Boot Program (NBP) corresponds to GRUB or LILO loaders typically used in local boots. Like a boot program in a hard drive environment, NBP is responsible for loading the operating system kernel into memory so that it can be bootstrapped over the network. Trivial File Transfer Protocol (TFTP) is a simple file transfer protocol typically used for automated transfers of configuration or boot files between machines in a local environment. However, when PXE is used, it serves to download the NBP over the network using the information obtained from the DHCP server. Intelligent Platform Management Interface (IPMI) is a standardized computer system interface used by system administrators to monitor their system and for handling the out-of-band management of their systems. This means that, due to a network connection being established directly with the hardware rather than just with the operating system, systems that do not respond or shut down can still be managed through IPMI.
The following figure shows how Ironic interacts with other OpenStack components when Ironic is used.
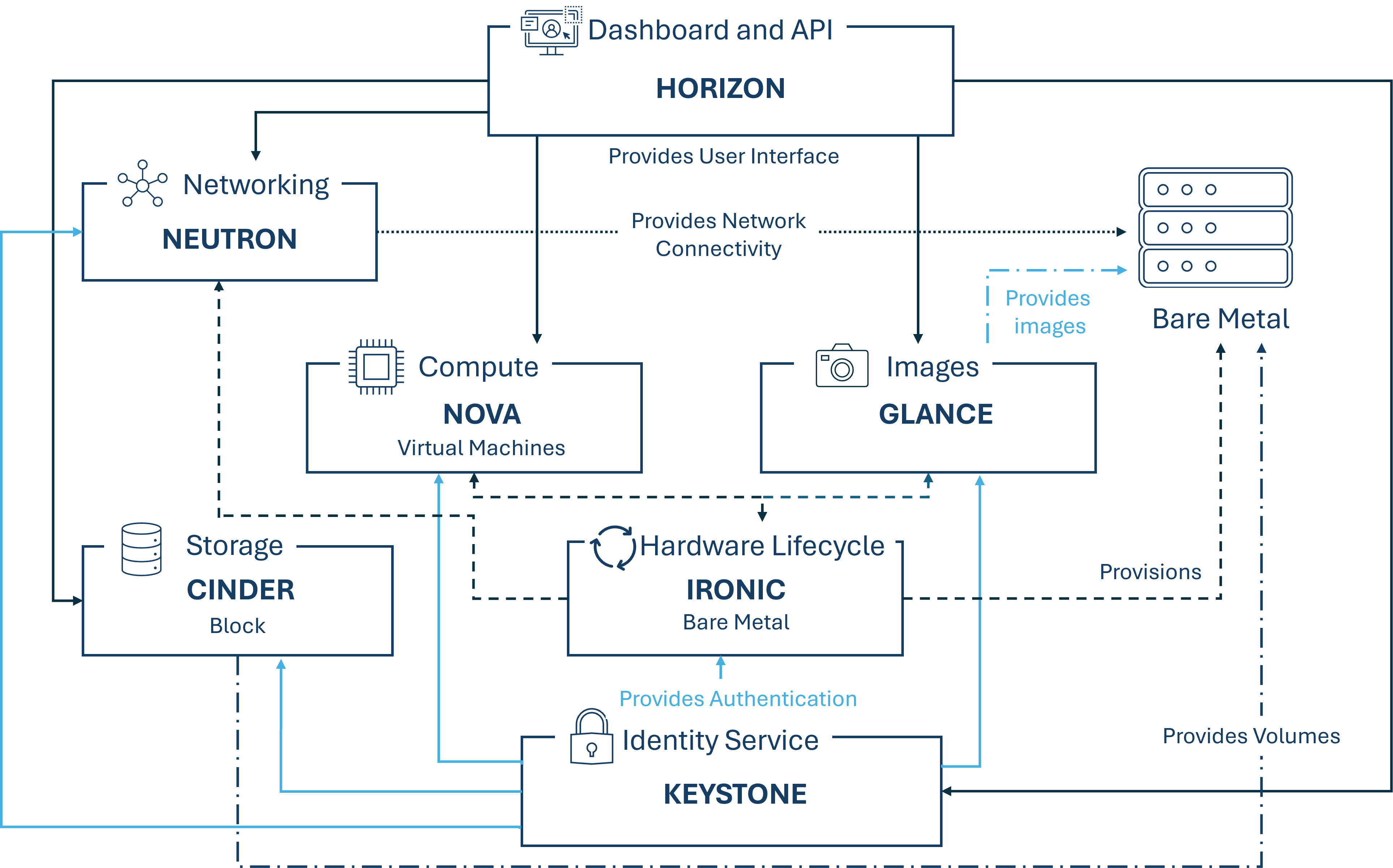
-
Keystone:
Keystone provides an API client authentication, service discovery, multi-tenant authorization, and identity management. Its primary functions are the management of users, domains and projects, also known as tenants, as well as authenticating users and services before granting them access to cloud resources. Additionally, it includes access control, which allows to enable or deny accesses based on roles and permissions. This component serves as the entry point for users and applications that want to access OpenStack resources or services.
How a such login via Keystone for accessing a resource works, is illustrated in the following figure.
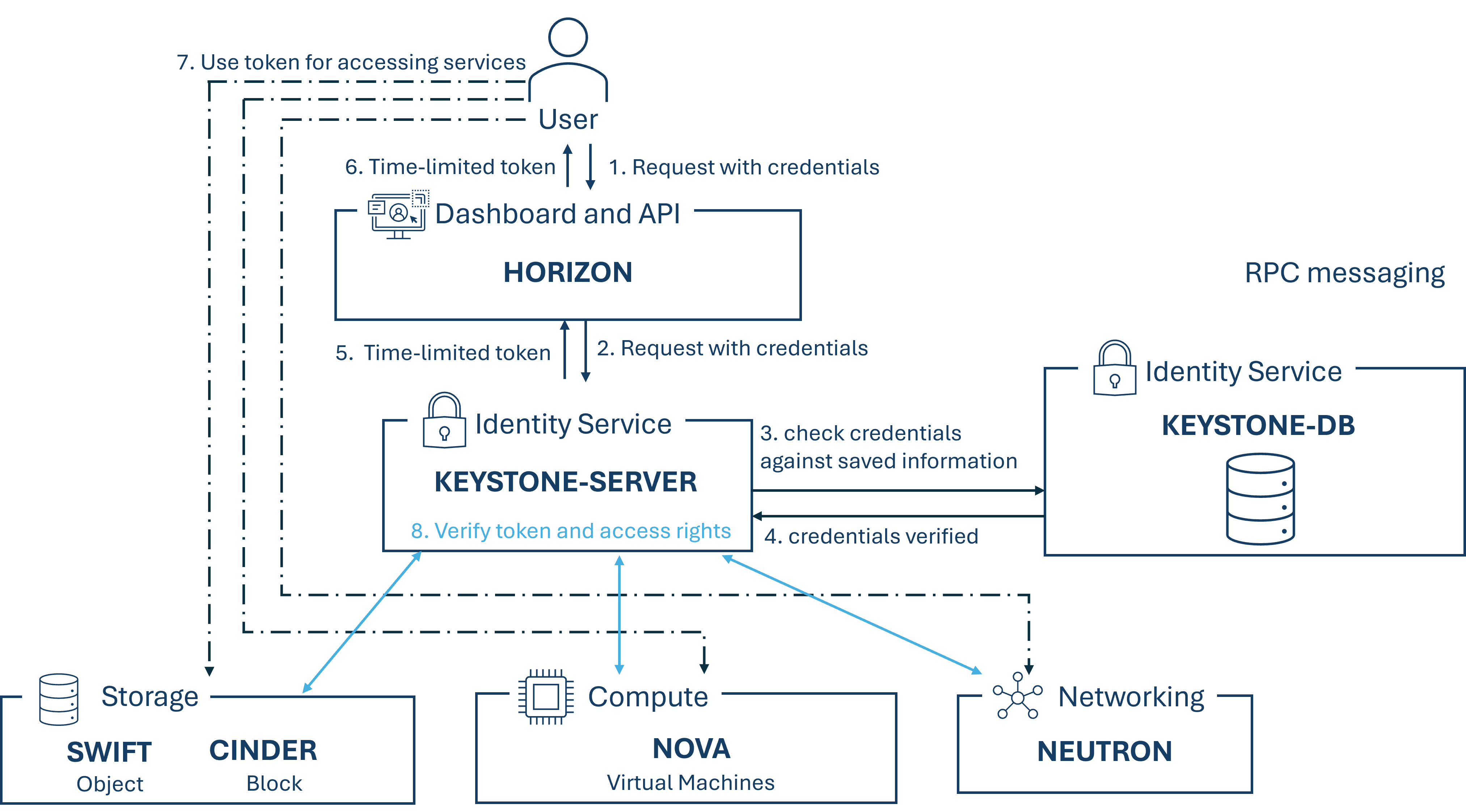
-
Placement:
Placement is responsible for tracking and managing the inventory of cloud resources and their utilization. This is necessary so that other services can efficiently manage and allocate these resources. Other services can register or unregister their resources with Placement through an HTTP API. When used together with Nova, Nova-Compute is responsible for creating a resource provider entry that must match the compute host on Placement, as well as setting the inventory which describes the quantitative resources available and adding qualitative attributes to the resources. Nova-Scheduler is responsible for selecting a set of suitable destination hosts. To make this selection, it first formulates a request for a list of possible candidates, which it passes to Placement, which then reduces the list using filters and weights. Such a list contains both quantitative and qualitative requirements, as well as memberships and in more complex cases also the topology of connected resources.
A resource provider can be, for example, a compute node, a shared storage pool, or an IP allocation pool. Different resource types are tracked as classes during allocation. A class can be a standard resource class like DISK_GB, MEMORY_MB, or VCPU, or a user-defined class can be created if needed.
-
Glance:
Glance is the OpenStack component responsible for discovering, registering, and retrieving virtual machine images. These images serve as templates for users to create new VM instances based on them. The actual image data is stored in various backends and made available to other OpenStack components for retrieval and use. Glance supports multiple image formats and allows metadata to be assigned to images, making them easier to find and manage.
Through its provided RESTful API, virtual machine image metadata can be queried and the actual images can be retrieved. By centrally managing disk images and due to the easy access to pre-configured images, Glance enables fast provisioning of virtual machines. Standardization and consistency is offered due to the use of uniform images for specific tasks, and efficient resource utilization is provided through the ability to reuse or share images.
The following diagram illustrates the process of adding an image to Glance and retrieving images from Glance, both from a user's perspective using Horizon and from the perspective of another OpenStack component, in this case Nova.
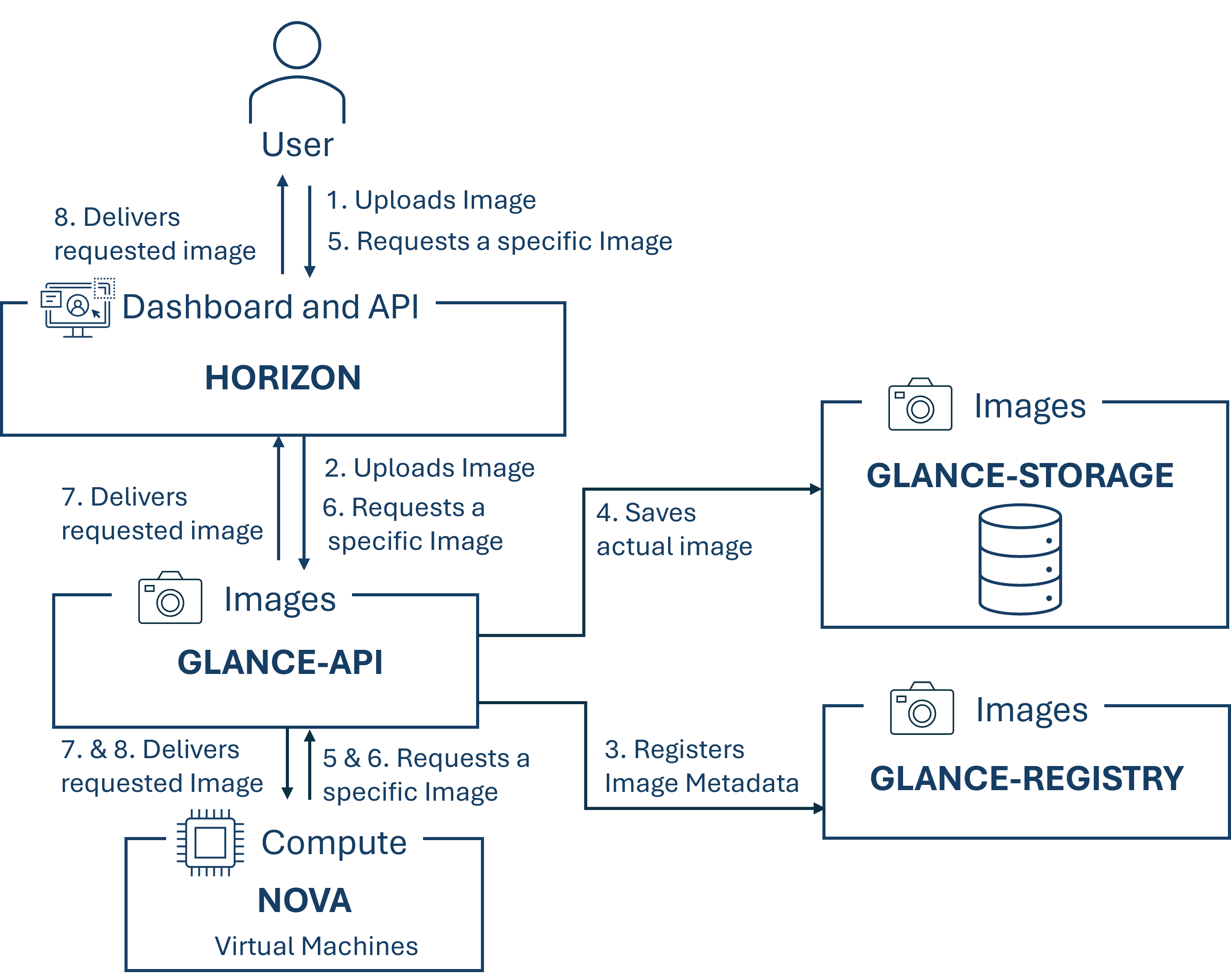
Glance depends on the component "Keystone".
¶ Dependencies between the components