¶ BlueBoxx-X3
Revolutionieren Sie die Stabilität und Leistungsfähigkeit Ihrer Enterprise-Unternehmens-IT:
Mit Blueboxx-X3 setzen Sie auf die ultimative Plattform für alle Ihre IT-Anwendungen. Durch die innovative Container-basierte Bereitstellung von OpenStack erreichen wir, was bisher als unerreichbar galt: Uneingeschränkte Ausfallsicherheit und zero Downtime für Ihre Infrastructure-as-a-Service (IaaS) - dank reibungsloser Rolling-Upgrades. Erleben Sie die Zukunft der Unternehmens-IT, heute mit Blueboxx-X3.
¶ Was bietet BlueBoxx-X3?
BlueBoxx-X3 bietet Unternehmen mehrere Vorteile:
-
Hochverfügbarkeit: Dies wird durch vollkommene Redundanz gewährleistet. BlueBoxx ist bis zur letzten Komponente voll redundant ausgelegt. Weiters gibt es dank dieses Aufbaus auch keinen Single-Point-of-Failure und wenn eine Aufteilung der BlueBoxx-Knoten auf unterschiedliche Brandabschnitte gewünscht wird, wird sogar eine Ausfallsicherheit bei Elementar-Ereignissen gewährleistet. Die Positionierung der Knoten kann sowohl am Betriebsstandort des Unternehmens, als auch in einem Rechenzentrum nach Wahl erfolgen.
-
Infrastructure as a Service: Die Openstack-Cluster-Daten werden in einer zentralen Datenbank zusammengefasst, was weitere Funktionen ermöglicht, wie zum Beispiel die Datenbalance zwischen mehreren Storage-Nodes. Wenn eine Node einen bestimmten Auslastungsgrad überschreitet, können die Daten oder VMs gemäß vorher definierter Aufteilungskriterien auf andere Nodes verschoben werden. Es ist auch möglich, dass ab einer bestimmten Auslastungsgrenze Instanzen in der Cloud hochgefahren und Daten oder VMs, gemäß vorher definierter Aufteilungskriterien, dorthin ausgelagert werden. Durch die Integration von Orchestrationservices wie Heat wird es ermöglicht, Infrastructure-as-a-Service (IaaS)-Umgebungen zu deployen und die Verwaltung von Ressourcen zu automatisieren. Weiters, können benötigte virtuelle Maschinen mittels API in Minutenschnelle provisioniert werden. Außerdem erleichtert die Bedienung mittels Dashboard die Handhabung. Im Dashboard können beispielweise neue VX:LANs angelegt werden oder neue VMs gespawnt werden. Zum Spawnen einer neuen VM muss nur das gewünschte Image, die RAM und Speichergrößen, das Speicher-Medium und die Art der Authentifizierung gewählt werden. Dieses einfache grafische User Interface erleichtert das Erstellen von VMs in dem nur Formulare ausgefüllt werden müssen, während die tatsächliche Umsetzung dann im Hintergrund anhand der Angaben verläuft.
-
High-Performance: In einer Welt, in der Geschwindigkeit zu einem entscheidenden Wettbewerbsfaktor geworden ist, bietet BlueBoxx die benötigte Leistung um voranzukommen. Unser innovatives Design, das auf den bewährten OpenStack-Komponenten basiert, sorgt durch die optimale Verbindung von Compute- und Storage-Nodes für eine bisher unerreichte High-Performance. Diese Architektur von BlueBoxx ermöglicht es selbst die anspruchsvollsten Workloads, wie die Ausführung rechenintensiver Anwendungen, dem bedarfsgerechten Skalieren von Ressourcen oder der Gewährleistung blitzschneller Datenzugriffe, ganz einfach zu bewältigen. Weiters ermöglicht BlueBoxx dank der direkten Kommunikation zwischen Compute- und Storage-Nodes die Reduktion der Latenzzeiten auf ein Minimum sowie die Maximierung der Gesamtdurchsatzrate. Dies bedeutet für unsere Kunden, dass Anwendungen schneller reagieren und somit auch die Benutzer zufriedener sind und das Geschäft agiler und wettbewerbsfähiger wird.
-
Near Zero Data Loss Backups: Dies wird mittels atomarer Snapshots der Gesamtumgebung sowie immutable Data-Protection gewährleistet. Klassische Backups sind daher nur mehr in Ausnahmefällen notwendig. Auch regelmäßige Restore-Tests und tägliches operatives Handling sind dank BlueBoxx nicht mehr erforderlich. Snapshot-Mechanismen unterhalb der Virtualisierungsschicht, die es ermöglichen, dass lokale Snapshots near-realtime auf beliebig viele Remote-Standorte verteilt werden, sind einer der Gründe für den Wegfall dieser Mehraufwände. Ohne Zusatzkosten oder Mehraufwand liegt dadurch das Recovery Point Objective lediglich im Minutenbereich, während das Recovery Time Objective sogar im Sekundenbereich liegt. Weiters sind die Snapshots selbst immutable, sind also gegen Veränderungen und "Man-in-the-Middle-Attacks" abgesichert und können dank zusätzlicher Verschlüsselung sogar in einer Public Cloud abgespeichert werden.
-
Kein Vendor Lock-in: Für die BlueBoxx werden ausschließlich Open-Source Lösungen verwendet, wodurch ein Vendor Lock-in verhindert wird. Dies bedeutet, dass Kunden nicht an spezifische Anbieter oder proprietäre Technologien gebunden sind, was häufig zu langfristigen Kostenfallen und eingeschränkter Flexibilität führt. Mit OpenStack als Fundament profitieren BlueBoxx-Kunden von der dynamischen Entwicklung einer globalen Community, die offen für Innovationen und Anpassungen an neue Technologietrends ist. Dies ermöglicht eine reibungslose Integration neuer Dienste und Funktionen, ohne die Einschränkungen proprietärer Ökosysteme. Weiters können unsere Kunden durch den Verzicht auf proprietäre Lösungen ihre IT-Infrastruktur an ihre Bedürfnisse anpassen, ohne sich um die Kompatibilität mit einem bestimmten Anbieter kümmern zu müssen. Ob Storage, Netzwerk oder Sicherheitslösungen – die Auswahl bleibt frei, solange sie den offenen Standards entsprechen.
-
Integrationspartnerschaft: Die heutige digitale Landschaft ist durch Vielfalt und Interoperabilität geprägt. Darüber hinaus sind wir bestrebt, im Sinne eines nachhaltigen Umgangs mit Ressourcen, die im Unternehmen vorhandene Hardware weiterzuverwenden. Deshalb verstehen wir bei BlueBoxx, wie wichtig eine nahtlose Integration mit bestehenden Systemen und Tools ist. Als verlässlicher Partner bieten wir maßgeschneiderte Integrationspartnerschaften, die darauf abzielen, BlueBoxx perfekt in die individuelle IT-Infrastruktur unserer Kunden einzubinden. Dank unseres Angebots 'Moving Migration' kann die Migration auf die bereits vorhandene Hardware sogar im laufenden Betrieb mit nur minimalen Downtimes stattfinden.
-
Automatisiertes Scaling: Durch Einsatz von MaaS werden hinzugefügte, physikalische Ressourcen automatisch erkannt und die IaaS erweitert. Bei Verbindung einer Ressource über ihr Remote Management Interface (IPMI, DRAC, iLO, etc.) werden die notwendigen Informationen ausgelesen und die Ressource provisioniert. Durch Analyse von Schwellenwerten und Ressourcendaten kann automatisch festgelegt werden, ob die Ressource als Compute- oder Storage-Node hinzugefügt werden soll. Basierend auf dieser Entscheidung wird die automatisierte Provisionsfunktion der Node mit den relevanten Containern ausgelöst.
-
Ransomware-Proof: Da alle 5 Minuten ein unveränderbarer und atomarer Snapshot gemacht wird, ist ein Rollback zu einem Zeitpunkt vor der Ransomware-Attacke innerhalb weniger Sekunden möglich. Selbst bei Treffen der besten Sicherheitsmaßnahmen, kann ein Hackerangriff der in der Verschlüsselung des gesamten Systems mündet, nicht immer verhindert werden. Dies kann laut Studien zu einem mehrtägigem Stillstand des gesamten Unternehmens führen. Mit BlueBoxx jedoch, kann eine vollständige und konsistente Wiederherstellung der gesamten Applikationswelt innerhalb von wenigen Minuten oder sogar Sekunden garantiert werden.
-
Flexible und skalierbare Netzwerkarchitektur: OpenStack Neutron bietet eine flexible und skalierbare Netzwerkarchitektur, die es ermöglicht, virtuelle Netze (VLANs) zu erstellen, VLAN-Verschlüsselung zu aktivieren und Firewall-Regeln zu definieren. Durch die Verwendung von Neutron können Administratoren ihre Netzwerkeffizienz steigern, indem sie sich auf die Bereitstellung von Netzwerkressourcen konzentrieren können. Darüber hinaus ermöglicht Neutron die Integration mit verschiedenen Network Functions Virtualization-Technologien (NFV), wie zum Beispiel Software-Defined Networking (SDN). Durch diese Integration können Unternehmen ihre Netzwerkeffizienz, -sicherheit und -skalierbarkeit verbessern.
-
Getestete Releases: Die kontinuierliche Verbesserung und Erweiterung von BlueBoxx ist für uns von höchster Priorität. Daher führt unser Team bei jedem neuen Release, bevor dieses live geht, ausführliche Tests durch, um sicherzugehen, dass BlueBoxx den strengsten Qualitäts- und Sicherheitsstandards genügt. Solche Releases können sowohl für Updates als auch für Neuerungen stattfinden. Dies beinhaltet sowohl automatisierte Tests als auch manuelle Prüfungen durch unsere Experten, um jede potenzielle Schwachstelle zu entfernen. Das Ergebnis sind Releases, die nicht nur innovative Funktionen bieten, sondern auch zuverlässig und sicher sind. Mit BlueBoxx profitieren unsere Kunden von der optimalen Balance zwischen Innovation und Stabilität.
-
Funktionsgarantie: Wir bei Sphinx stehen voll und ganz hinter der Qualität und Leistungsfähigkeit unserer BlueBoxx-Plattform. Deshalb bieten wir unseren Kunden eine umfassende Funktionsgarantie. Sollten jemals Probleme mit der Funktionalität von BlueBoxx auftreten, die nicht durch unsere proaktive Wartung verhindert werden konnten, kümmern wir uns in enger Zusammenarbeit mit unseren Kunden darum, die Ursache zu identifizieren und eine Lösung auszuarbeiten, die den Betrieb unseres Kunden so wenig wie möglich stört.
-
Full Management: BlueBoxx wird als Managed Service vom Sphinx-Team betreut. Managed Service bedeutet in diesem Fall, dass unser erfahrenes Team kontinuierlich alle Komponenten von BlueBoxx überwacht um sicherzustellen, dass jeder Aspekt der Plattform – von der Infrastruktur bis hin zu den Anwendungen – reibungslos funktioniert. Durch proaktive Wartung und sofortige Reaktion auf potenzielle Probleme minimieren wir Ausfallzeiten und garantieren eine maximale Uptime für kritische Workloads. Mit BlueBoxx kann sich unser Kunde voll und ganz auf sein Kerngeschäft konzentrieren, während wir im Hintergrund dafür sorgen, dass alles läuft wie erwartet.
-
7 x 24 proaktives Monitoring: Ein proaktiver Ansatz ist der Schlüssel zum Vermeiden von Problemen, bevor sie überhaupt auftreten. Deshalb legen wir bei unserer Lösung BlueBoxx großen Wert auf ein umfassendes Monitoring aller Systemaspekte. Unser leistungsstarkes Überwachungssystem liefert Echtzeit-Einblicke in die Performance, Sicherheit und Integrität der Plattform, ermöglicht frühzeitige Warnungen bei potenziellen Problemen und ermöglicht es unserem Team, korrektive Maßnahmen zu ergreifen, oft sogar bevor unsere Kunden überhaupt etwas von einem Problem mitbekommen.
-
Third-Level Support: Ein hervorragender Support ist das Fundament jeder erfolgreichen Lösung. Wir bieten für BlueBoxx einen Third-Level-Support, der über die üblichen Servicestandards hinausgeht. Während First- und Second-Level-Supports oft nur allgemeine Anfragen und grundlegende technische Probleme abdecken, ist unser Third-Level-Support speziell für komplexe, tiefgehende technische Herausforderungen ausgelegt. Unsere Experten auf diesem Gebiet arbeiten direkt mit Entwicklern und Systemarchitekten zusammen, um individuelle Lösungen für besonders anspruchsvolle Probleme zu entwickeln. Mit diesem Spitzen-Support stellen wir sicher, dass selbst die komplexesten Herausforderungen keine Hürde für den Erfolg unserer Kunden darstellen.
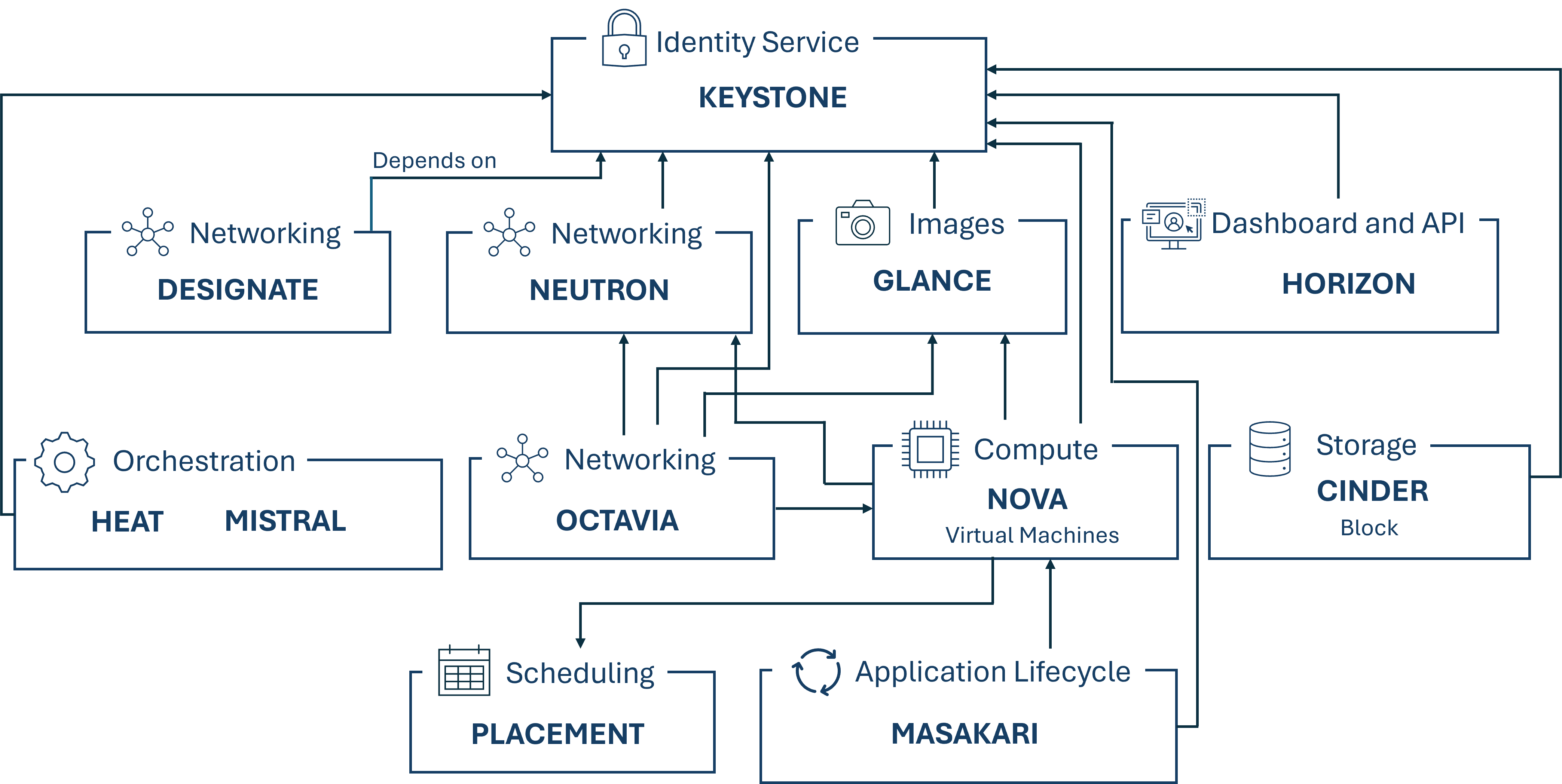
¶ BlueBoxx-X3 Infrastruktur
Die folgende Abbildung zeigt die Infrastruktur, sowie die von uns verwendeten OpenStack-Komponenten unser BlueBoxx-X3-Lösung.
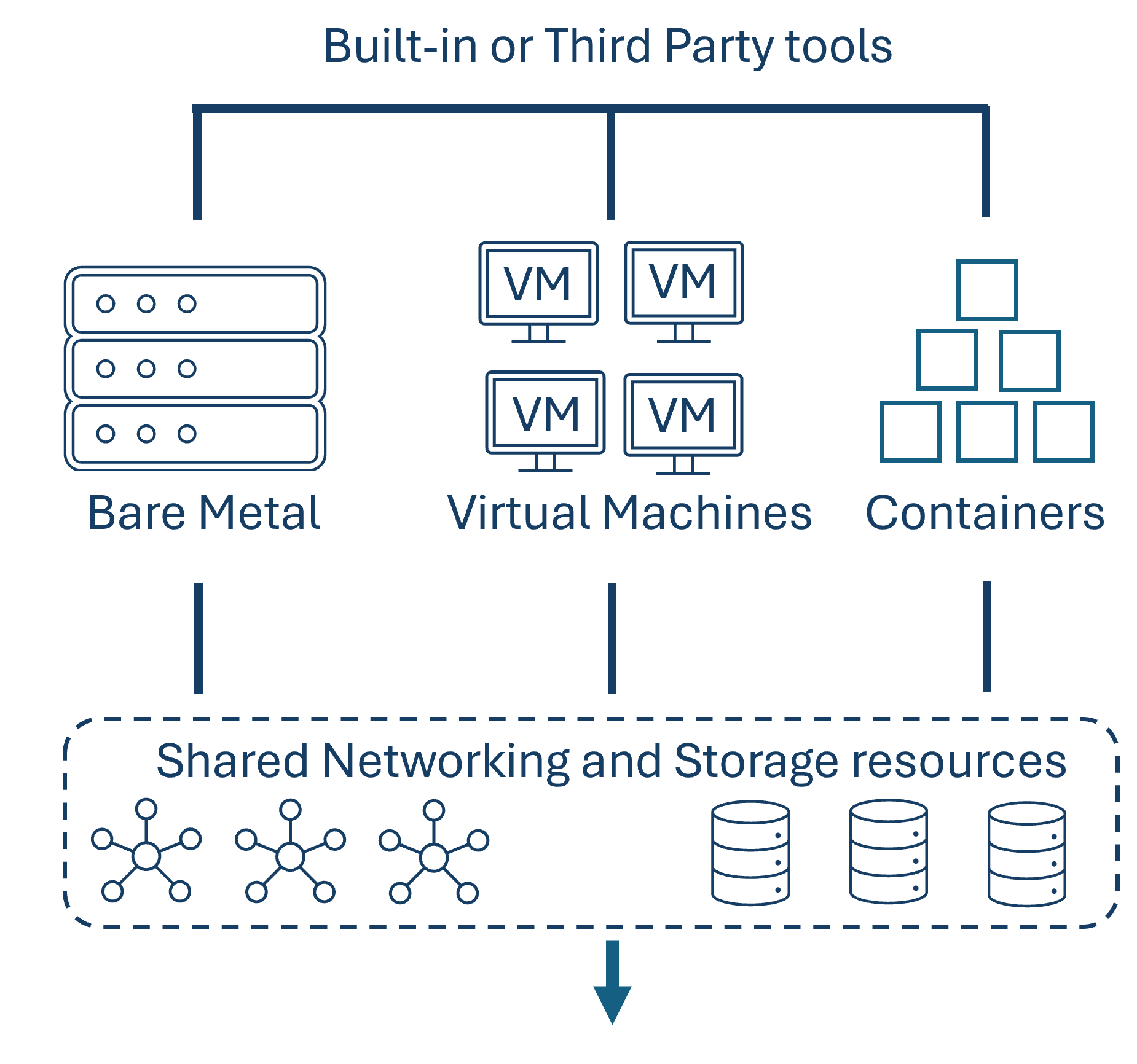
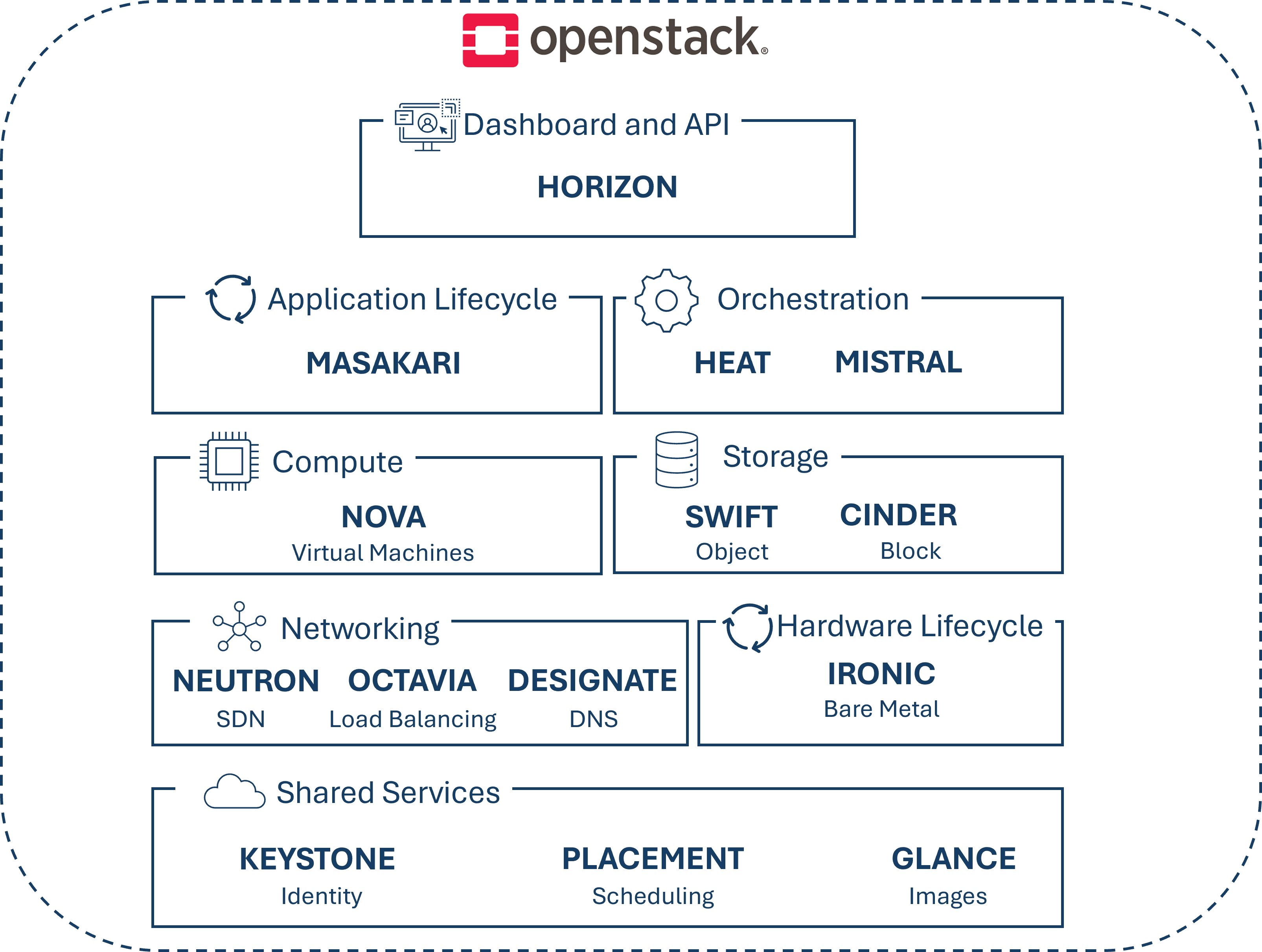
¶ Verwendete Komponenten
Folgend der von uns verwendete Teil des OpenStack-Service-Stacks.
-
Horizon:
Dies ist das OpenStack Dashboard, welches ein web-based User Interface zu den OpenStack Services, wie Nova, Swift oder Keystone anbietet. Weiters, können hier Einstellungen zu Nodes durchgeführt werden, wie beispielweise die Größe eines neues Storage-Space oder welcher Treiber verwendet werden soll.
Horizon wurde als Registrierungsmuster für Applikationen gebaut, damit sich diese darüber einfach ankoppeln können. Heutzutage wird Horizon mit drei zentralen Dashboards geliefert: "User Dashboard", "System Dashboard" und "Settings Dashboard". Diese drei Dashboards decken alle Core-OpenStack Application ab und liefern den Core Support.
Die Horizon Dashboard Applikation basiert auf der Dashboard-Klasse, welche eine konsistente API, sowie ein Set an Fähigkeiten sowohl für mitgelieferte Core OpenStack Dashboard Applikationen als auch für Third-Party Applikation anbietet. Diese Dashboard-Klasse wird als Top-Level Navigations-Posten behandelt. Wenn ein Entwickler oder eine Entwicklerin eine bestimmte Funktionalität in ein bereits bestehendes Dashboard hinzufügen möchte, ist das dank des einfachen Registrierungsmusters, welches es ermöglicht eine neue Applikation zu schreiben, die sich an andere Dashboards ankoppelt, genau so einfach wie ein neues Dashboard zu erstellen. Dafür muss lediglich das Dashboard importiert werden, das verändert werden soll.
Um Files davon abzuhalten tausende von Zeilen lang zu werden und Code leichter findbar zu machen, indem er direkt mit der Navigation korreliert, wird in OpenStack eine einfache Methode zur Registrierung von Panels angeboten. Diese stellen jeweils die gesamte notwendige Logik eines Interfaces dar und zählen zu den Sub-Navigations-Posten.
Horizon hängt von der Komponente "Keystone" ab.
-
Masakari:
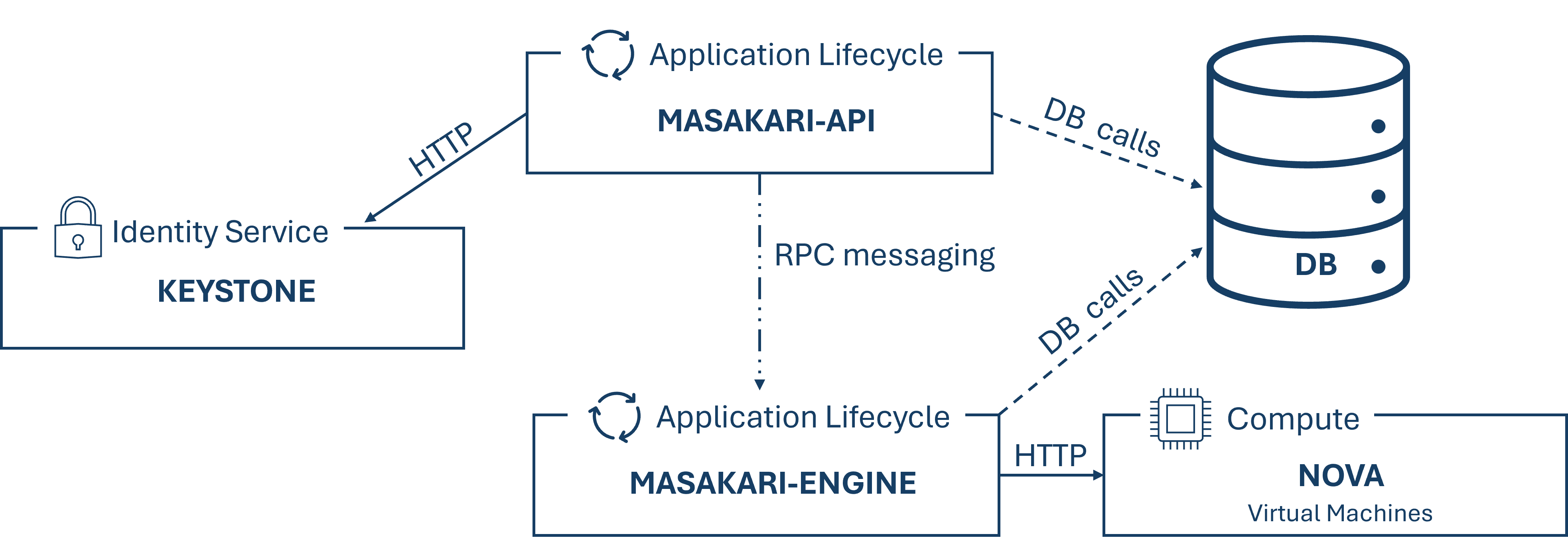
Masakari bietet für OpenStack Clouds ein Instanzen Hochverfügbarkeitsservice an, indem es fehlgeschlagene Instanzen oder Compute-Prozesse automatisch wiederherstellt. Um diesen automatischen Wiederherstellungsmechanismus zu managen und zu kontrollieren, bietet Masakari zusätzlich ein API Service dafür an. Es kann KVM-basierte virtuelle Maschinen von Fehlern wie virtueller Maschinenprozess down, Provisionierungsprozess down oder einem nova-compute Host Fehler aus wiederherstellen.
Masakari besteht aus zwei Services einer API und einer Engine, welche unterschiedliche Funktionen durchführen. Der API Server verarbeitet REST-Anfragen, welche üblicherweise Datenbank read/write Aufrufe beinhalten, konvertiert die Befehle, sendet daraufhin RPC Nachrichten an die Engine und generiert Antworten zu den REST-Anfragen. Die Engine läuft auf dem selben Host wie die API und hat einen Manager welcher einerseits auf RPC Nachrichten reagiert und andererseits periodische Tasks zum Durchführen hat. Weiters führt die Engine den Recovery Workflow aus und kommuniziert via HTTP mit Nova. Außerdem hängt Masakari von den OpenStack-Komponenten "Keystone" und "Nova" ab. Der Aufbau der Kommunikation dieser Schlüssel-Komponenten wird in der folgenden Abbildung dargestellt.
-
Heat:
Heat ist eine OpenStack-Komponente zur Orchestrierung von Infrastruktur Ressourcen für Cloud Applikationen. Diese Orchestrierung findet mittels Templates in der Form von Text-Dateien statt, welche wie Code behandelt werden können. Ein solches Template beschreibt die Infrastruktur einer Cloud Applikation in einer für Menschen leserbaren und schreibbaren Art und ermöglicht ein Management mittels Version-Control-Tools. Da diese Templates die Beziehungen zwischen den Ressourcen beschreibt, ermöglicht das Heat den OpenStack APIs die richtige Reihenfolge zur Erstellung der geplanten Infrastruktur mitzuteilen, so das die darauf aufbauende Applikation hochgefahren werden kann. Mit diesen Templates können die meisten OpenStack Ressourcen Typen, wie Instanzen, Floating IPs, Volumes, Security Groups und Users, erstellt werden. Außerdem bieten sie auch fortschrittlichere Funktionalitäten wie Instance High Availabilty, Autoscaling von Instanzen und Nested Stacks an. Dieses Autoscaling Services ermöglicht die Einbindung von OpenStack Telemetry und somit auch das Einbinden von Scaling Gruppen als eine Ressource in einem Template. Heat ist zwar in erster Linie zum Managen von Infrastruktur gedacht, aber die Templates lassen sich auch sehr gut in Software Konfigurationsmanagement Tools wie Ansible und Puppet integrieren.
Heat bietet sowohl eine OpenStack native ReST API an, als auch eine Cloud-Formation kompatible Query API. Heat hängt von der Komponente "Keystone" ab.
-
Mistral:
Mistral ist ein Workflow-Service. Die meisten Business-Prozesse bestehen aus mehreren verschiedenen voneinander abhängigen Schritten welche in einem Verteilten System einer bestimmten Reihenfolge durchgeführt werden müssen. Ein solcher Prozess kann als ein Set von Tasks und deren Beziehungen zueinander beschrieben werden. Dies geschieht meist in einer YAML-basierten Sprache. Eine solche Beschreibung kann bei Mistral hochgeladen werden, damit dieses sich um das State Management, die richtige Durchführungsreihenfolge, Parallelismus, Synchronisation und High Availabilty kümmern kann.
Tasks die mittels Mistral ausgeführt werden, können alles sein, vom Durchführen lokaler Prozesse wie shell scripts und binaries auf einer bestimmten virtuellen Instanz, das Aufrufen von REST APIs die in einem Cloud Environment erreichbar sind bis hin zu Cloud Management Tasks wie das Erstellen oder Löschen von virtuellen Instanzen. Auch verschachtelte Workflows können mittels Mistral ausgeführt werden, indem es nach Durchführung des neuen Workflows mit den vorgegebenen Variablen wieder zurück in den Parent Workflow springt und dort beim gleichen Punkt wieder weiter macht. Mistral ist vor allem wichtig wenn mehrere Tasks zu einem einzigen Workflow zusammengefasst werden sollen, die entweder in einer bestimmten Reihenfolge oder zu einem bestimmten Zeitpunkt durchgeführt werden sollen. Hier sorgt Mistral nämlich für eine parallele Durchführung der voneinander unabhängigen Tasks, Fehlertoleranz falls eine Node während der Durchführung eines mehrstufigen Workflows abstürzen sollte und ein Workflow Durchführungsmanagement sowie Monitoring Capabilities. Mistral selbst führt keine Tasks aus, sondern koordiniert die anderen Worker Prozessse, welche die eigentliche Arbeit durchführen und dann die Ergebnisse Mistral berichten. Während Mistral den Usern bereits ein Set von Standard Aktionen für Tasks liefert, ermöglicht es Usern auch benutzerdefinierte Aktionen basierend auf dem Standard Paket anzulegen. Zum darstellen der in Mistral verwendeten Workflows kann das Workflow Visualisierungstool "CloudFlow" verwendet werden. Eine solche Darstellung kann auch hilfreich sein um Fehler oder Schwachstellen in einem Workflow zu finden.
Mistral hängt von der Komponente "Keystone" ab.
-
Nova:
Nova wird zur Provisionierung von Compute-Instanzen verwendet. Es unterstützt das Erstellen von virtuellen Maschinen, in Zusammenarbeit mit Ironic auch das Erstellen von Bare Metal Servern und hat zusätzlich einen limitierten Support für System Container und stellt diese Ressourcen per Self-Service-Plattform zur Verfügung. Nova ist modular aufgebaut um Skalierbarkeit, Flexibilität und Wartungsfreundlichkeit zu gewährleisten. Zu dieser Flexibilität trägt auch bei, dass Nova verschiedene Hypervisors unterstützt und somit eine breite Palette an Virtualisierungstechnologien abdeckt. Einer dieser Hypervisor ist VMWareESX welche zur VMware-Produktfamilie gehört, wodurch der Zugriff für virtuelle Maschinen auf erweiterte Funktionen wie vMotion, Hochverfügbarkeit und dynamische Ressourcenzuweisung (DRS) ermöglicht wird. Nova kann somit mit dem vCenter-Server, der VMwareESX API kommunizieren, welcher wiederum einen oder mehrere ESX-Host-Cluster verwaltet. Diese Cluster werden Nova als eine große Hypervisor-Entität präsentiert. Die tatsächliche Auswahl des ESX-Hosts innerhalb dieses Clusters erfolgt dann durch vCenter mithilfe von DRS. Es wird empfohlen, pro ESX-Cluster einen Nova-Compute-Dienst zu betreiben. Weiters sind bei Nova, durch die Kommunikation über eine API, die Hypervisor austauschbar, solange ein entsprechender Treiber vorhanden ist.
Nova besteht aus den Modulen API, Scheduler, Compute und Conductor. Während das API-Modul API-Anfragen von Benutzern und anderen OpenStack Diensten empfängt und bearbeitet sowie die Authentifizierung mittels Integration mit Keystone für eine Zugriffsverwaltung und zur Sicherheit übernimmt, kümmert sich das Scheduler Modul, basierend auf verfügbaren Ressourcen und Filterkriterien, um die optimale Verteilung der Last über die verfügbaren Ressourcen, indem es entscheidet auf welchen Compute-Node eine neue virtuelle Instanz gestartet werden soll. Das Compute Modul managed die virtuellen Maschinen auf den Compute Nodes, indem es diese startet, stoppt, ändert oder löscht und bietet eine Hypervisor-Unterstützung für unterschiedliche Hypervisors wie Hyper-V, VMware, Xen oder KVM. Das letzte Modul, der Conductor, bietet eine vertrauenswürdige Umgebung für sensitive Operationen an, welche zur Erhöhung der Sicherheit nicht direkt auf den Compute-Nodes durchgeführt werden sollen. Außerdem kann dieses Modul die Aufgaben von anderen Nova-Komponenten übernehmen, um deren Last zu reduzieren.
Wie diese Module miteinander interagieren um eine Instanz zu erstellen, kann der folgenden Grafik entnommen werden.
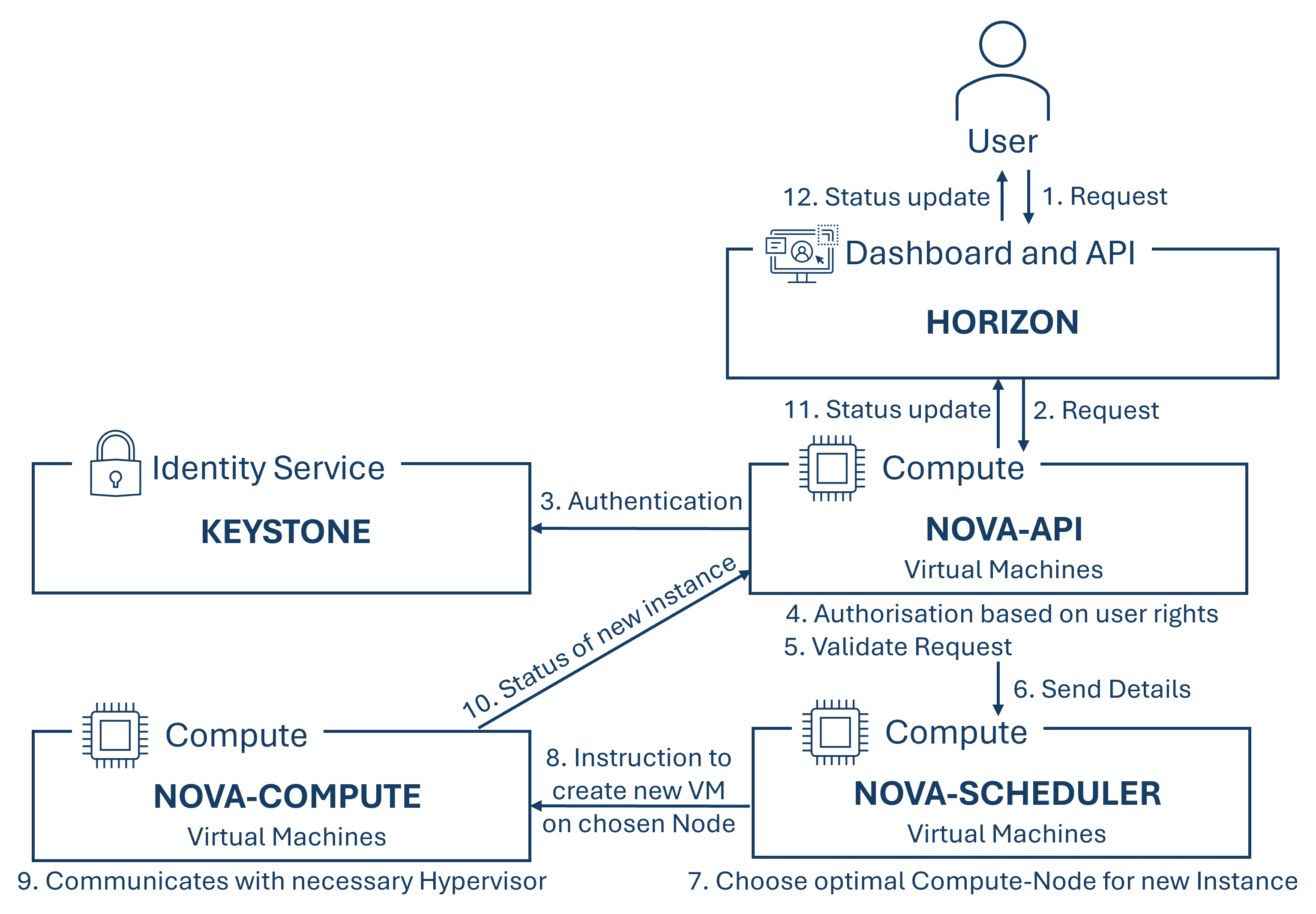
Nova hängt von den Komponenten "Keystone", "Neutron", "Glance" und "Placement" ab.
-
Swift:
Swift ist ein verteilter, hochverfügbarer und schlussendlich konsistenter Objekt- oder Blob-Store. Mithilfe von Swift können Unternehmen Daten effizient, sicher und billig speichern. Es ist für Skalierung ausgelegt und wurde für Dauerhaftigkeit (Durability), Verfügbarkeit (Availability) und den gleichzeitigen Zugriff über das ganze Datenset hinweg (Concurrency) optimiert. Swift ist ideal um unstrukturierte Daten abzuspeichern, welche ohne Grenze wachsen können. Dies ist möglich, da Objekt-Stores eine verteilte Architektur verwenden, bei der es keine zentrale Kontrolle gibt, sondern Objekte werden auf mehreren Hardware Devices abgespeichert und Swift kümmert sich um die Replikation und Integrität der Daten die auf dem Cluster verteilt sind. Die Storage Cluster sind horizontal skalierbar, indem neue Nodes hinzugefügt werden können. Sollte eine Node ausfallen, sorgt Swift dafür dass die Daten auf die anderen aktiven Nodes repliziert werden. Da sich Swift um die Replikation und Verteilung der Daten kümmert, können für die Storage Cluster günstige, herkömmliche Hard Drives und Server verwendet werden und somit auch ein Vendor Lock-In verhindert werden. Weitere Vorteile von Objekt-Stores sind deren selbst-heilende Fähigkeiten, unlimitierter Speicherplatz, die einfache Skalierbarkeit, High Availability, bessere Performance aufgrund des Wegfalls eines Bottlenecks da es keine zentrale Datenbank gibt, die Möglichkeit ein Expiry Date für Objekte zu setzen sowie die Möglichkeit Restriktionen für Container per Account zu setzen, um den Zugriff zu beschränken, sowie der direkte Zugriff zu Objekten und dass keine RAIDs benötigt werden.
Charakteristika von Objekt-Stores sind:
- Jedes Objekt besitzt eine URL.
- Es können unterschiedliche "Storage Policies" angelegt werden um unterschiedliche Level von Dauerhaftigkeit für Objekte im Cluster anzulegen.
- Alle Objekte besitzen eigene Metadaten.
- Objektdaten können sich an einer beliebigen Stelle des Clusters befinden.
- Neue Nodes können dem Cluster ohne Downtime hinzugefügt werden.
- Fehlerhafte Nodes oder Disks können ohne Downtime getauscht werden.
- Es kann handelsübliche Hardware für die Cluster verwendet werden.
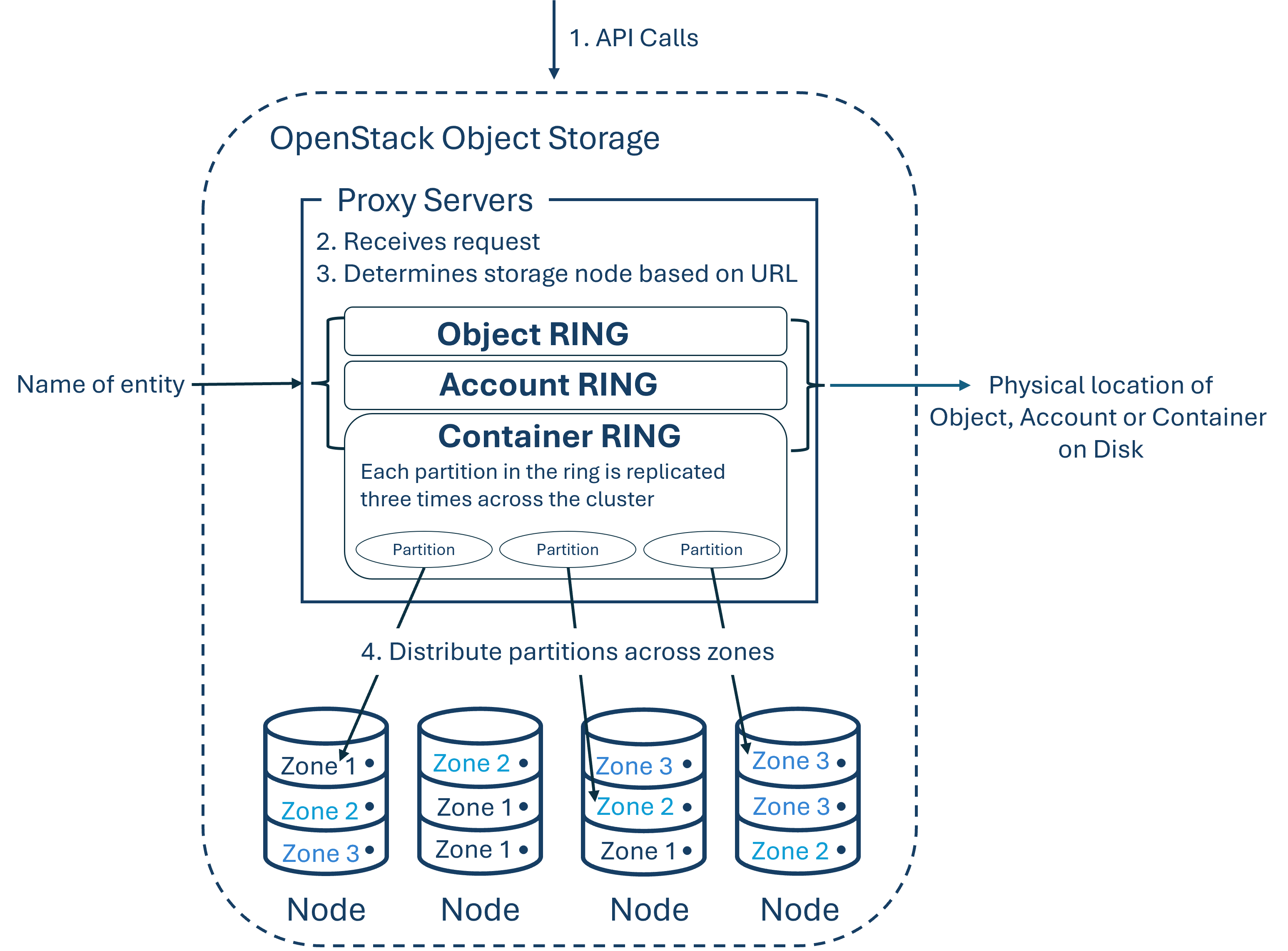
Ein Objekt-Store besteht aus mehreren Komponenten um High Availability, High Durability und High Concurrency bieten zu können. Proxy Server kümmern sich um eingehende API-Anfragen, Rings ordnen logische Namen von Daten deren Speicherorte auf einer bestimmten Disk zu, Zonen isolieren Daten unterschiedlicher Zonen voneinander, so dass ein Fehler in einer Zone keinen Einfluss auf den restlichen Cluster hat, da die Daten über mehrere Zonen verteilt repliziert wurden und Objekte sind die Daten selbst. Weiters gibt es Accounts und Containers. Jeder einzelne davon ist eine individuelle Datenbank, welche über den Cluster verteilt ist. Während die Account-Datenbank eine Liste aller Container die zu diesem Account gehören beinhaltet, führt eine Container-Datenbank eine Liste aller Objekte in diesem Container. Partitionen speichern Objekte, Account-Datenbanken und Container-Datenbanken und helfen beim Managen der Speicherorte wo diese Daten am Cluster gespeichert sind.
Diese Komponenten und wie sie miteinander interagieren sind in der folgenden Abbildung dargestellt.
-
Cinder:
Cinder ist ein Block Storage Service und virtualisiert das Management von Block Storage Devices. Dadurch können End-User mittels API diese Ressourcen anfragen und benutzen ohne Wissen zu müssen wo sich dieser Speicher tatsächlich befindet oder auf welcher Art von Device sich der Speicherplatz befindet. Cinder stellt diese blockbasierten Speicherressourcen als Volumes für Nova virtuelle Maschinen, Ironic Bare Metal Hosts und Container zur Verfügung. Der Vorteil eines solchen Volumes ist es, dass sie unabhängig von der Lebensdauer einer virtuellen Maschine existieren können. Das heißt, auch nach Löschen einer virtuellen Maschine bleiben die Daten erhalten. Außerdem ist es sehr einfach Volumes an virtuelle Maschinen anzuhängen und auch wieder von einer virtuellen Maschine abzuhängen, was eine flexible Ressourcenzuweisung ermöglicht. Aufgrund von Cinder's Unterstützung von einer Vielzahl an Speicher-Backends, wie lokalen Festplatten oder externen Storage-Systemen, wie NAS, SAN oder Ceph, kann der bestehende Speicher effizient genutzt werden. Außerdem bietet Cinder Funktionen zum Erstellen von Snapshots und Backups. Weiters ist es dank seiner Komponenten basierten Architektur möglich neue Verhaltensmuster schnell hinzuzufügen und Cinder bietet aufgrund seiner Skalierbarkeit auch eine High Availability. Außerdem ist es Fault-Tolerant, da kaskadierende Fehler mittels isolierter Prozesse vermieden werden und wenn Fehler auftreten ist Cinder wiederherstellbar, da Fehler einfach diagnostiziert, ge-debugged und behoben werden können. Das Horizon User Interface kann zum Erstellen und Managen von Volumes via Cinder verwendet werden.
Cinder hängt von der Komponente "Keystone" ab.
-
Neutron:
Neutron ist ein Software-definiertes Netzwerk Projekt, welches Networking-as-a-Service (NaaS) in virtuellen Rechnerumgebungen bietet. Es ermöglicht somit das Erstellen und Verwalten von Netzwerken, sowie die Konfiguration der Netzwerkfunktionen für virtuelle Maschinen innerhalb der Cloud. Aufgrund der offenen Architektur von Neutron, ist die Integration mit verschiedenen Netzwerktechnologien und -geräten möglich. Außerdem bietet es Funktionalitäten wie VX:LANs und Firewall-as-a-Service (FWaaS) an. Durch VX:LANs ist die Anzahl der möglichen virtuellen LANs nicht beschränkt, wie es bei VLANs der Fall wäre. Neutron leitet virtuelle Netzwerke an physische Netzwerke mittels Network Address Translation (NAT) weiter.
Um ein neues virtuelles Netzwerk mittels Neutron zu konfigurieren, kann ein Administrator zuerst ein neues virtuelles Netzwerk inklusiver aller Subnetze, Routen und Sicherheitsgruppen via Horizon erstellen und diese Konfigurationsanfragen werden dann von Neutron verarbeitet. Es setzt diese dann in der physischen Netzwerkinfrastruktur um, indem es mit den entsprechenden Plug-ins und Agenten kommuniziert. Diese konfigurierten Netzwerke können dann bei Erstellung einer virtuellen Maschine durch Auswahl des Passenden, ganz einfach zugewiesen werden.
Neutron hängt von der Komponente "Keystone" ab.
-
Octavia:
Octavia ist die Load-Balancing Komponente von OpenStack. Indem es seine Flotte an virtuellen Maschinen, Containern und Bare Metal Servern, auch Amphore genannt, auf Anfrage hochfährt, um der Aufgabe nach Lastenverteilung nachzukommen, unterscheidet diese horizontale Skalierungsfunktion Octavia von anderen Load Balancing Lösungen und macht es somit wirklich für die Cloud geeignet.
Octavia ist dafür zuständig den Incoming Network Traffic auf mehrere Server aufzuteilen, um eine High Availability und optimale Ressourcenauslastung zu gewährleisten. Mehrere Treiber werden unterstützt und Octavia kann in Neutron integriert werden.
Octavia verwendet einige OpenStack Komponenten um ihren Aufgaben nachkommen zu können.-
Nova: Um den Amphoren Lebenszyklus zu managen, sowie Compute-Ressourcen auf Anfrage hochzufahren
-
Neutron: Für die Netzwerkverbindungen zwischen der Amphore, den Tenant-Umgebungen und dem externen Netzwerk
-
Keystone: Zur Authentifizierung gegenüber der Octavia API sowie anderen OpenStack Projekten gegenüber
-
Glance: Um die virtuellen Maschinen-Images abzuspeichern
-
Oslo: Für die Kommunikation zwischen den einzelnen Octavia Controller Komponenten.
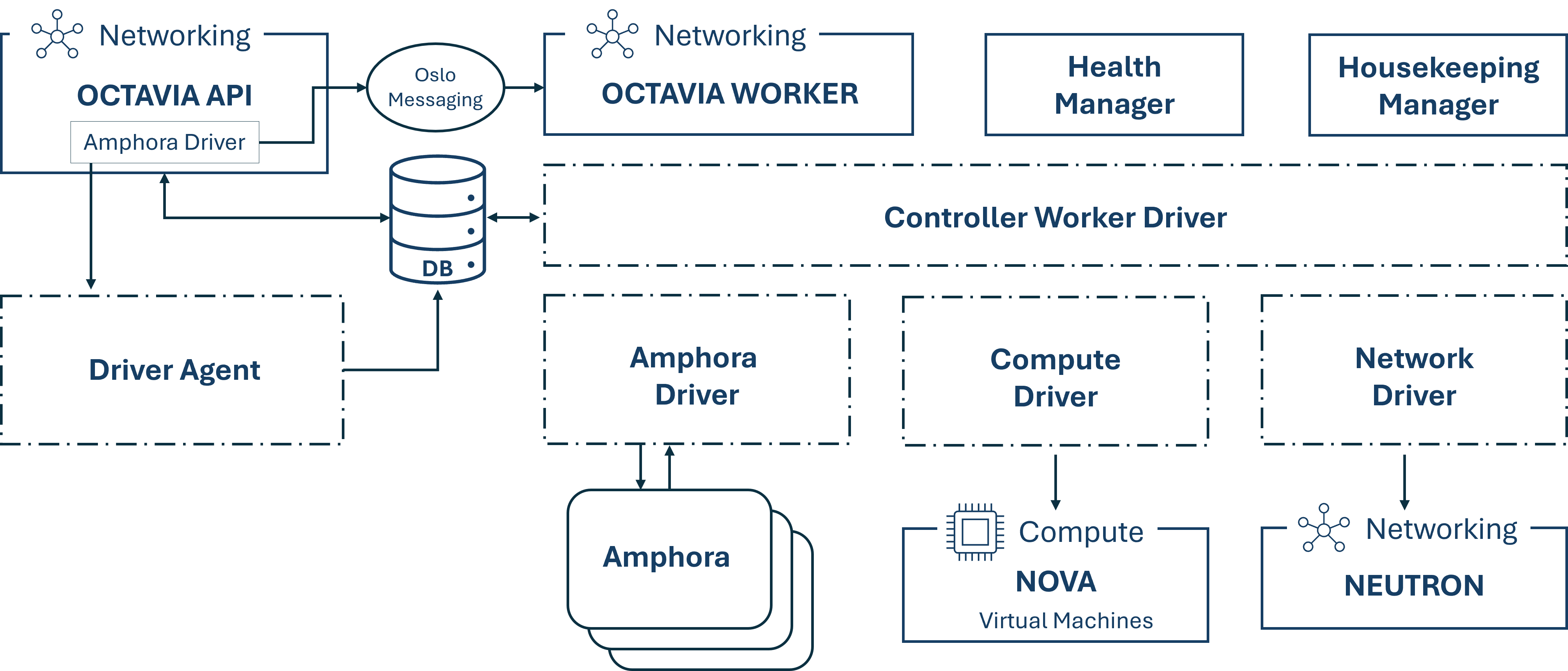
Weiters, besteht der Octavia Controller, welcher das Gehirn von Octavia ist, aus 5 Komponenten, welchen individuelle Daemons sind und somit auf unterschiedlichen Back-Ends laufen können. Der API Controller nimmt API Anfragen entgegen, unterzieht diese einer einfachen "Reinigung" und leitet sie dann via Oslo Messaging Schnittstelle an den Controller Worker weiter. Dieser nimmt die gereinigte Anfrage entgegen und leitet alle Aktionen, die zur Erfüllung der Anfrage notwendig sind, ein. Der Health Manager beobachtet die einzelnen Amphoren um sicherzugehen, dass alle laufen und gesund und kümmert sich um das Failover, falls eine unerwartet ausfällt. Der Housekeeping Manager räumt geläschte Datenbanken auf. Die letzte Komponente, der Driver Agent, bekommt vom Provider Driver Status und Statistik Updates.
Die folgende Abbildung zeigt die Kommunikation der einzelnen Octavia Komponenten untereinander sowie mit den anderen OpenStack Komponenten.
-
Octavia hängt von den Komponenten "Keystone", "Glance", "Neutron" und "Nova" ab.
-
Designate:
Diese Komponente sorgt für DNS-as-a-Service. Es bietet eine REST API mit integrierter Keystone Authentifizierung, sowie die Möglichkeit einer Konfiguration zur automatischen Generierung von Records basierend auf Nova und Neutron Aktionen. Weiters unterstützt es eine Vielzahl von DNS Servern, wie Bind9 oder PowerDNS 4.
Designate besteht aus fünf verschiedenen Services, der API, dem Producer, dem Central, dem Worker und dem Mini-DNS. Mehrere Kopien von jedem dieser Services können gleichzeitig laufen um eine High Availability zu gewährleisten. Weiters verwendet Designate eine oslo.db kompatible Datenbank zum Speichern der Daten und deren Stati, sowie eine oslo.messaging kompatible messaging queue für die Kommunikation zwischen den Services.
Wenn Netzwerke in Neutron erstellt werden, die einer Zone die in Designate angelegt wurde hinzugefügt wird, wird beim späteren hinzufügen einer virtuellen Maschine in einem dieser Netzwerke, automatisch ein Eintrag am Designate Nameserver hinzugefügt. Dieses Update der Zonen-Information wird von dem Worker angestoßen und die aktualisierten Informationen dann von der Mini DNS abgefragt. Es wird daraufhin sowohl ein Forward- als auch ein Reverse-Eintrag im Nameserver hinzugefügt.
Designate hängt von der Komponente "Keystone" ab.
-
Ironic:
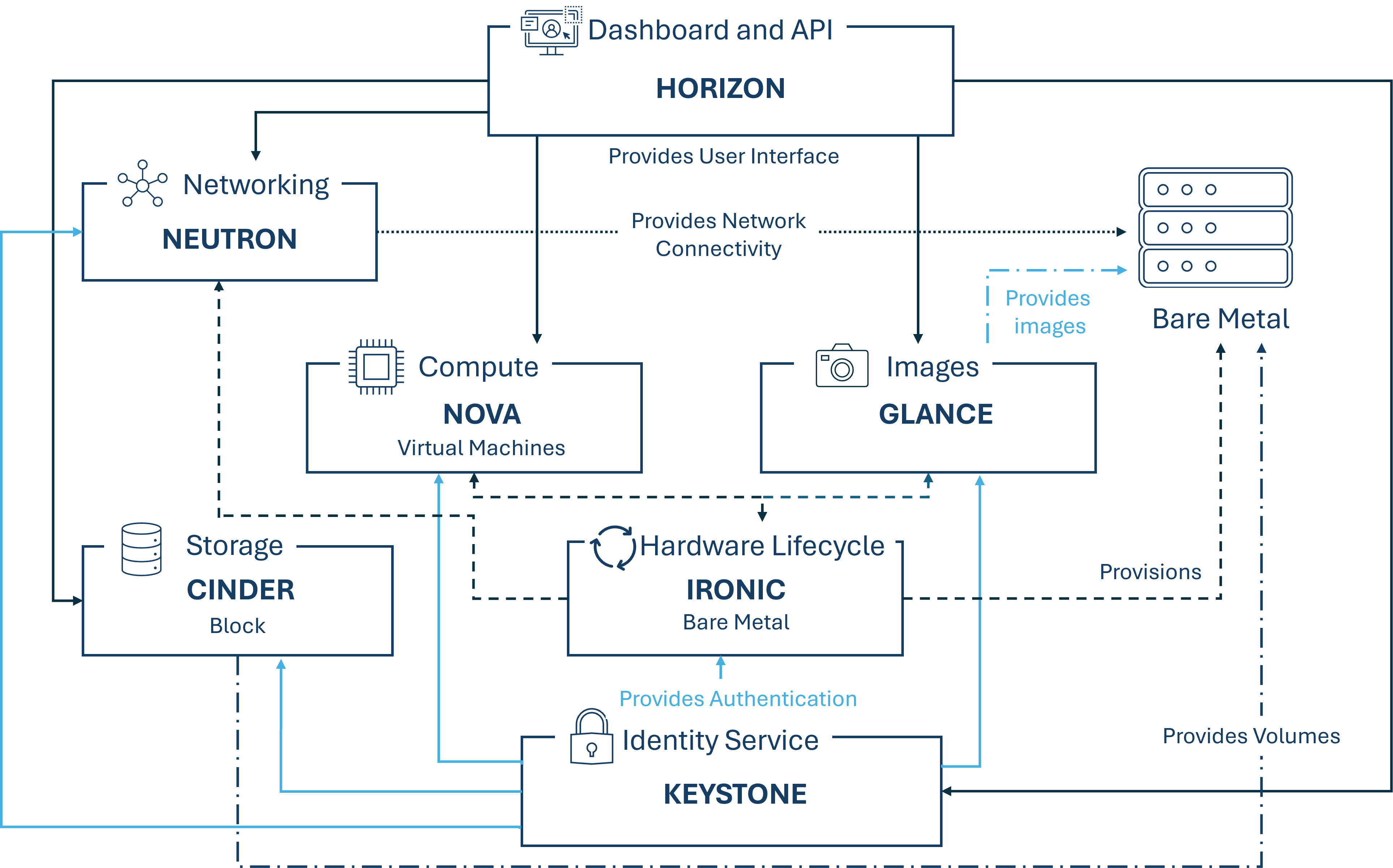
Ironic ist die Komponente welche für die Provisionierung von Bare-Metal-Maschinen zuständig ist. Es sind Integrationen mit Keystone, Nova, Neutron, Glance und Swift möglich. Ironic ermöglicht das managen der Hardware sowohl mit handelsüblichen, PXE und IPMI, sowie Verkäufer-spezifischen Remote Management Protokollen. Weiters bietet es den Anwendern ein einheitliches Interface zu der heterogenen Masse an Servern, sowie ein Interface für die Compute Komponente Nova, mittels der sie physische Server so managen kann, als wären sie virtuelle Maschinen.
Bare Metal Server werden in der Cloud für unterschiedliche Zwecke provisioniert, doch einige der wichtigsten sind High-Performance Computing Cluster und Computing Tasks die den Zugriff zu Hardware Devices benötigen welche nicht virtualisiert sein dürfen. Schlüsseltechnologien für Bare Metal Hosting sind PXE, DHCP, NBP, TFTP und IPMI. Preboot Execution Environment (PXE) ermöglicht es dem System BIOS und der Netzwerk Interface Card (NIC) einen Computer vom Netzwerk aus, statt von einer Disk aus zu bootstrappen. Bootstrapping ist der Prozess bei dem das System das Betriebssystem in den lokalen Speicher lädt, damit dieses vom Prozessor ausgeführt werden kann. Dynamic Host Configuration Protocol (DHCP) verteilt dynamisch Netzwerk-Konfigurationsparameter, wie beispielweise IP Adressen für Interfaces und Services. Bei der Verwendung von PXE, verwendet das BIOS DHCP um eine IP Adresse für das Netzwerk Interface zu bekommen, damit es den Server finden kann auf welchem das Netzwerk Bootstrap Programm abgespeichert ist. Das Netzwerk Bootstrap Programm (NBP) entspricht den GRUB oder LILO Loadern welche üblicherweise bei einem lokalen Boot verwendet werden. Gleich wie bei einem Boot Programm in einer Hard Drive Umgebung, ist NBP dafür zuständig, dass der Betriebssystem Kernel in den Speicher geladen wird, damit dieser über das Netzwerk geboottrapped werden kann. Trivial File Transfer Protocol (TFTP) ist ein einfaches Dateienübertragungsprotokoll, welches üblicherweise für automatisierte Übertragungen von Konfigurations- oder Boot-Dateien zwischen Maschinen in einer lokalen Umgebung verwendet wird. Wenn jedoch PXE verwendet wird, dient es zum Download der NBP über das Netzwerk, für dass es die Informationen vom DHCP Server bekommen hat. Intelligent Platform Management Interface (IPMI) ist ein standardisiertes Computer System Interface, welches von Systemadministratoren dafür verwendet werden kann, um deren Systeme zu monitoren, sowie für das Out-of-Band Management ihrer Systeme. Das heißt, da es eine Netzwerk Verbindung direkt mit der Hardware und nicht nur mit dem Betriebssystem gibt, können Systeme die nicht reagieren oder heruntergefahren sind, dennoch gemanaged werden.
Die folgende Abbildung zeigt wie Ironic mit den anderen OpenStack Komponenten interagiert, wenn Ironic verwendet wird.
-
Keystone:
Keystone bietet eine API Client Authentifizierung, Service-Erkennung, Multi-Tenant Autorisierung und Identitätsverwaltung. Die Hauptfunktionen sind die Verwaltung von Benutzern, Domänen und Projekten, auch Tenants gennant, sowie die Authentifizierung von Benutzern und Diensten bevor diese Zugriff auf die Cloud-Ressourcen erhalten. Weiters gehört die Zugriffssteuerung dazu, welche Zugriffe basierend auf Rollen und Berechtigungen ermöglicht oder verbietet. Diese Komponente dient somit als Eintrittspunkt für Benutzer und Anwendungen, welche auf OpenStack Ressourcen oder Dienste zugreifen möchten.
Wie eine solche Anmeldung via Keystone für einen Zugriff zu einer Ressource abläuft, wird in der folgenden Abbildung dargestellt.
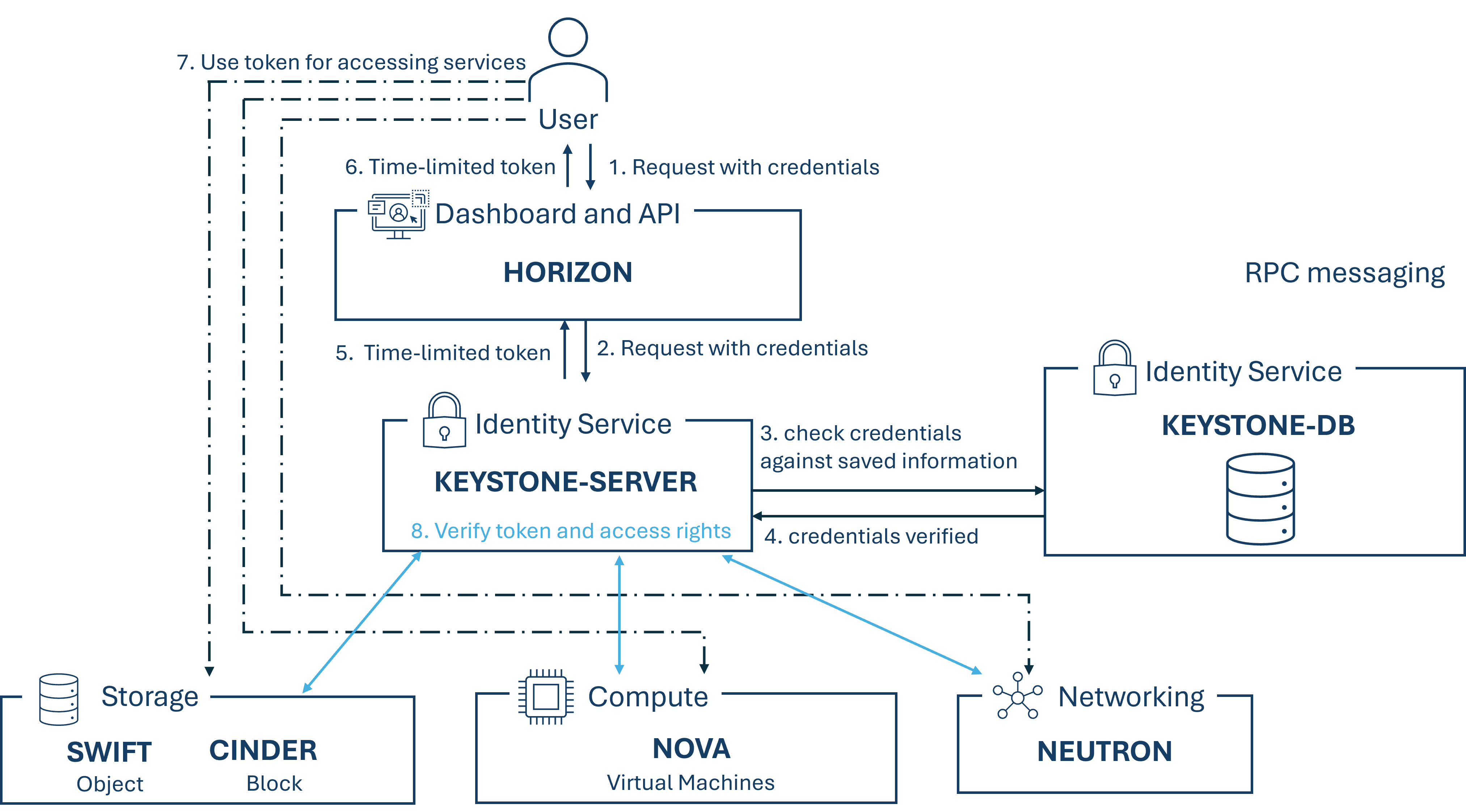
-
Placement:
Placement dient zur Verfolgung des Cloud Ressourcenbestands und deren Verwendung. Dies ist notwendig, damit andere Services deren Ressourcen effizient managen und vergeben können. Andere Services können deren Ressourcen bei Placement mittels HTTP API registrieren oder wieder löschen.
Wenn Nova gemeinsam mit Placement verwendet wird, ist Nova-Compute für das Erstellen eines Ressourcen-Providereintrags verantwortlich, welcher mit dem Compute Host auf dem Placement läuft übereinstimmen muss, sowie dem Setzen des Bestands, welcher die quantitativen Ressourcen beschreibt die zur Verfügung stehen und dem Hinzufügen der qualitativen Merkmale der Ressourcen. Nova-Scheduler ist für die Auswahl eines Sets an passenden Destination Hosts verantwortlich. Um diese Auswahl treffen zu können, formuliert er zuerst eine Anfrage nach einer Liste von möglichen zuweisbaren Kandidaten, welcher er an Placement weiterleitet und reduziert diese Liste dann anhand von Filtern und Gewichten. Eine solche Liste enthält quantitative und qualitative Anforderungen, sowie Mitgliedschaften und in komplexeren Fällen auch die Topologie der verbundenen Ressourcen.
Ein Ressourcen-Provider kann beispielweise eine Compute-Node, ein geteiltes Storage Pool oder ein IP Allocation Pool sein. Die unterschiedlichen Ressourcen-Typen werden bei Vergabe als Klassen verfolgt. Eine solche Klasse kann beispielweise eine Standardressourcenklasse wie DISK_GB, MEMORY_MB oder VCPU sein. Weiters können auch benutzerdefinierte Klasssen erzeugt werden, wenn diese benötigt werden.
-
Glance:
Glance ist die OpenStack Komponente welche für das Finden, Registrieren und Abrufen von virtuellen Maschinen Images zuständig ist. Diese Images dienen dazu, damit Benutzer neue VM-Instanzen basierend auf diesen Vorlagen erstellen können. Die eigentlichen Image-Daten werden in verschiedenen Backends abgespeichert und anderen OpenStack-Komponenten für den Abruf und die Nutzung zur Verfügung gestellt. Glance unterstützt mehrere Image-Formate und erlaubt die Zuweisung von Metadaten zu Images, damit diese leichter auffindbar und verwaltbar sind. Mittels der von Glance angebotenen RESTful API können virtuellen Maschinen Image Metadaten abgefragt werden und die tatsächlichen Images abgerufen werden. Durch die zentrale Verwaltung von Disk-Images sowie des einfachen Zugriffs auf vorkonfigurierte Images ermöglicht Glance eine schnelle Bereitstellung von virtuellen Maschinen. Eine Standardisierung und Konsistenz wird aufgrund der Verwendung von einheitlichen Images für bestimmte Aufgaben ermöglicht und eine effiziente Ressourcennutzung wird durch die Möglichkeit Images wiederzuverwenden oder zu teilen zur Verfügung gestellt.
Die nachfolgende Abbildung zeigt den Ablauf wie ein Image bei Glance hinzugefügt werden kann sowie wie Images von Glance abgefragt werden können und zwar sowohl aus Sicht eines User mittels Horizon als auch aus Sicht einer anderen OpenStack-Komponente in diesem Fall Nova.
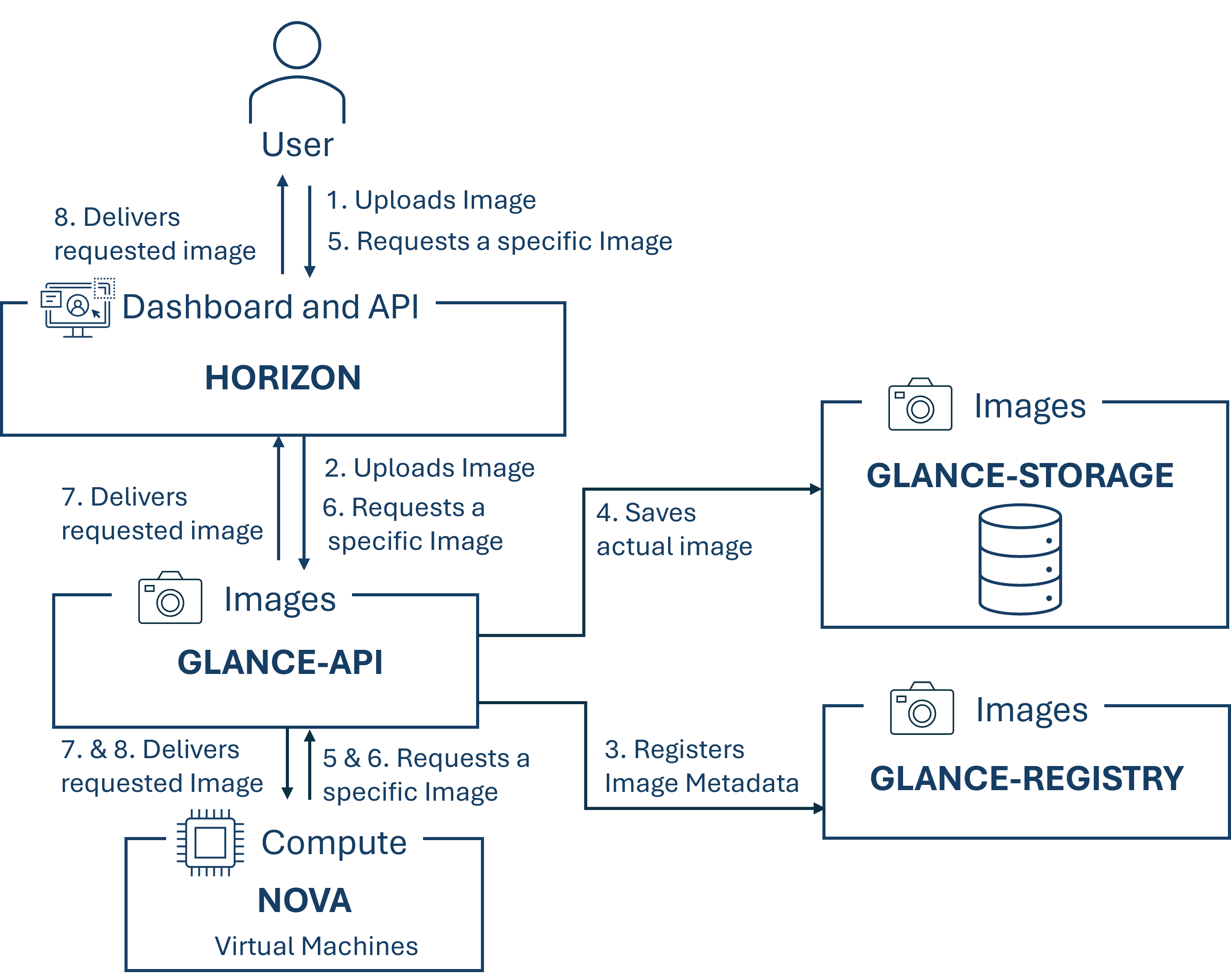
Glance hängt von der Komponente "Keystone" ab.
¶ Abhängigkeiten zwischen den Komponenten